CASO PRÁCTICO - AUTO ESCALANDO LOS NODOS WORKERS
Para hacer la prueba de auto escalado de nuestros nodos workers, vamos a borrar el clúster creado durante el apartado de Kubernetes Operations, pero antes vamos a salvar algunos valores que nos interesan para poder replicar un nuevo clúster pero más pequeño :-).
echo "export AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID
export AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY
export AWS_DEFAULT_REGION=$AWS_DEFAULT_REGION
export ZONES=$ZONES
export NAME=$NAME
export BUCKET_NAME=$BUCKET_NAME
export KOPS_STATE_STORE=$KOPS_STATE_STORE
export CLUSTER_DNS=$CLUSTER_DNS" \
>cluster-autoscaler/kops-clusterincoming
Cargar las variables de entorno Simplemente bastaría con ejecutar "source ~/cluster-autoscaler/kops-clusterincoming"
En este caso como el clúster va ser mas reducido, vamos a establecerlo a una sola AZ para la prueba, por lo tanto lo indicamos a la variable ZONES:
ZONES=eu-west-1a
Eliminar el clúster antiguo
Borramos el clúster anteriores si lo tuviéramos:
➜ kops delete cluster \
--name $NAME \
--yes
Eliminar también el S3 Bucket, donde se almacenaba el estado deseado del Clúster:
➜ aws s3api delete-bucket \
--bucket $BUCKET_NAME
Desplegar un clúster con nodos pequeños
Primero crear el bucket:
aws s3api create-bucket \
--bucket $BUCKET_NAME \
--create-bucket-configuration \
LocationConstraint=$AWS_DEFAULT_REGION
{
"Location": "http://proyecto-1527665818.s3.amazonaws.com/"
}
Ahora si crear el cluster:
kops create cluster \
--name=${NAME} \
--zones=${ZONES} \
--master-size="t2.small" \
--node-size="t2.micro" \
--node-count="2" \
--ssh-public-key proyecto.pub \
--kubernetes-version="1.7.6" --yes
....
kops has set your kubectl context to proyecto.k8s.local
Cluster is starting. It should be ready in a few minutes.
....
El clúster tarda unos 5 minutos en estar disponible.
Verificamos que los nodos estan disponibles en nuestro clúster:
➜ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-172-20-39-165.eu-west-1.compute.internal Ready master 1m v1.7.6
ip-172-20-42-153.eu-west-1.compute.internal Ready node 20s v1.7.6
ip-172-20-44-25.eu-west-1.compute.internal Ready node 24s v1.7.6
Desplegar un add-on para monitorzar dentro del clúster
➜ kubectl create -f https://raw.githubusercontent.com/kubernetes/kops/master/addons/monitoring-standalone/v1.7.0.yaml
deployment.extensions "heapster" created
service "heapster" created
serviceaccount "heapster" created
clusterrolebinding.rbac.authorization.k8s.io "heapster" created
role.rbac.authorization.k8s.io "system:pod-nanny" created
rolebinding.rbac.authorization.k8s.io "heapster-binding" created
Desplegar el add-on Cluster Autoscaler
Antes de proceder a desplegar dicho add-on, vamos a ajustar los valores minSize y maxSize del ASG de los workers:
kops edit ig nodes
Opcional: Si no, nos defendemos con el editor vi, podemos asignar la ruta del binario de otro editor, antes de ejecutar la instrucción anterior. Por ejemplo: EDITOR=/bin/nano.
Una vez abierto con el editor de texto, modificar los valores por, maxSize a 4 y minSize a 2:
apiVersion: kops/v1alpha2
kind: InstanceGroup
metadata:
creationTimestamp: 2018-06-11T21:11:53Z
labels:
kops.k8s.io/cluster: proyecto.k8s.local
name: nodes
spec:
image: kope.io/k8s-1.9-debian-jessie-amd64-hvm-ebs-2018-03-11
machineType: t2.micro
maxSize: 4
minSize: 2
nodeLabels:
kops.k8s.io/instancegroup: nodes
role: Node
subnets:
- eu-west-1a
Procedemos a actualizar el estado de seado de nuestro clúster a AWS:
kops update cluster $NAME --yes
IAM policy
Posteriormente necesitamos, asociar una nueva política al role de nodes.proyecto.k8s.local, para que sea capaz de leer el estado del propio ASG y cambiar el valor Desired.
Creamos un fichero policy-cluster-autoscaler.json, con el siguiente código dentro:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"autoscaling:DescribeAutoScalingGroups",
"autoscaling:DescribeAutoScalingInstances",
"autoscaling:DescribeTags",
"autoscaling:SetDesiredCapacity",
"autoscaling:TerminateInstanceInAutoScalingGroup"
],
"Resource": "*"
}
]
}
Ahora ejecutamos la instrucción desde línea de comandos, para asociarsela al rol:
aws iam put-role-policy --role-name nodes.${NAME} \
--policy-name asg-nodes.${NAME} \
--policy-document file://policy-cluster-autoscaler.json
Configurando el manifest del cluster auto-scaler
Colocamos nuestros datos en estas variables de entorno:
CLOUD_PROVIDER=aws
IMAGE=k8s.gcr.io/cluster-autoscaler:v1.1.0
MIN_NODES="2"
MAX_NODES="4"
AWS_REGION=eu-west-1
GROUP_NAME="nodes.proyecto.k8s.local"
SSL_CERT_PATH="/etc/ssl/certs/ca-certificates.crt"
Fijaremos el nombre del fichero yml a crear en una variable, una vez nos descargemos la “plantilla” del repositorio oficial de kops.
addon=cluster-autoscaler.yml
wget -O ${addon} https://raw.githubusercontent.com/kubernetes/kops/master/addons/cluster-autoscaler/v1.8.0.yaml
Luego procedemos a sustituir los valores de la plantilla, por los de nuestro clúster:
sed -i -e "s@@${CLOUD_PROVIDER}@g" "${addon}"
sed -i -e "s@@${IMAGE}@g" "${addon}"
sed -i -e "s@@${MIN_NODES}@g" "${addon}"
sed -i -e "s@@${MAX_NODES}@g" "${addon}"
sed -i -e "s@@${GROUP_NAME}@g" "${addon}"
sed -i -e "s@@${AWS_REGION}@g" "${addon}"
sed -i -e "s@@${SSL_CERT_PATH}@g" "${addon}"
Ahora si podemos iniciar el deployment del add-on:
➜ kubectl apply -f ${addon}
serviceaccount "cluster-autoscaler" created
clusterrole.rbac.authorization.k8s.io "cluster-autoscaler" created
role.rbac.authorization.k8s.io "cluster-autoscaler" created
clusterrolebinding.rbac.authorization.k8s.io "cluster-autoscaler" created
rolebinding.rbac.authorization.k8s.io "cluster-autoscaler" created
deployment.extensions "cluster-autoscaler" created
Podemos comprobar que efectivamente se ha levantado un pod para él, en el namespace de kube-system:
➜ kubectl get pods --namespace=kube-system
NAME READY STATUS RESTARTS AGE
cluster-autoscaler-1251066907-d49gh 1/1 Running 0 42s
El pod del cluster auto-scaler se despliega en un nodo master.
Desplegar una aplicación demo
Vamos a utilizar una aplicación demo de la documentación de Kubernetes, básicamente es una imagen docker personalizada basada en un apache con php. En su interior aloja un index.php que lo que tiene es un bucle con un cálculo exponencial, para ir aumentando el uso de cpu.
kubectl run php-apache --image=gcr.io/google_containers/hpa-example \
--requests=cpu=200m --expose --port=80
service "php-apache" created
deployment.apps "php-apache" created
Ahora procedemos a crear el auto-escalado para nuestras aplicación, la cual se mantendrá entre 2-20 pods, según el promedio de cpu de los pods, en este caso hemos fijado el valor a 5%.
Este valor es demasiado bajo, pero es simplemente para el proposito de la prueba. No usar este valor en producción.
kubectl autoscale deployment php-apache --cpu-percent=5 --min=2 --max=20
deployment.apps "php-apache" autoscaled
Ahora tocaría esperar unos minutos, para que el auto escalador, inicie la monitorización de la carga de los pods y poder visualizar que este el valor fijado a 0% ya que no esta recibiendo peticiones el apache hasta ahora.
➜ kubectl get hpa php-apache
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/5% 2 20 2 2m
En la versión 1.9.6 de Kubernetes he tenido problemas para poder monitorizar con el add-on.
Por otro lado podemos ver las dos replicas que se han levantado:
➜ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
php-apache-593471247-3bmfw 1/1 Running 0 3m 100.96.2.4 ip-172-20-33-66.eu-west-1.compute.internal
php-apache-593471247-kqshk 1/1 Running 0 2m 100.96.1.5 ip-172-20-38-203.eu-west-1.compute.internal
Ver el servicio ClusterIP para acceder al php-apache localmente:
➜ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 100.64.0.1 <none> 443/TCP 10m
php-apache ClusterIP 100.68.217.24 <none> 80/TCP 4m
Simular carga de trabajo contra el sitio web
Procedemos a hacer la prueba de carga contra los containers desde dentro del propio nodo worker, que tiene acceso local:
Podemos ver el endpoint para conectarnos a uno de los workers desde la consola de AWS, en el apartado de EC2. Y utilizamos la clave privada, que asociamos a los nodos a la hora de levantar el clúster y que pertenecen al usuario kopsuser en nuestro AWS.
➜ ssh -i "proyecto.pem" admin@34.245.199.148
Y acto seguido ejecutamos un bucle en bash desde la propia terminal contra la dirección IP del Cluster IP asociada al servicio que esta escuchando en el puerto 80:
while true; do wget -q -O- http://100.68.217.24; done
Verificar que nuestro clúster y los pods de la aplicación se auto escalan
Acto seguido, al poco tiempo si vamos comprobando el numero de replicas irán creciendo con el paso del tiempo hasta el máximo de 20 pods que hemos fijado, podemos consultar:
Los pods:
➜ kubectl get pods
NAME READY STATUS RESTARTS AGE
php-apache-593471247-1l2fv 0/1 Pending 0 2m
php-apache-593471247-2cjg5 0/1 Pending 0 2m
php-apache-593471247-3bmfw 1/1 Running 0 22m
php-apache-593471247-7j2kv 1/1 Running 0 2m
php-apache-593471247-90f84 1/1 Running 0 6m
php-apache-593471247-jf0px 0/1 Pending 0 2m
php-apache-593471247-jnnc6 1/1 Running 0 6m
php-apache-593471247-kqshk 1/1 Running 0 21m
php-apache-593471247-l1b8x 1/1 Running 0 6m
php-apache-593471247-npfb2 1/1 Running 0 2m
php-apache-593471247-q41r0 1/1 Running 0 10m
php-apache-593471247-vdlfj 1/1 Running 0 2m
Y por otro lado monitorizar, como va elevándose el uso de cpu y va aumentando el número de replicas, a medida que dispone de nodos nuevos para levantar dentro de él, los pods:
➜ kubectl get hpa php-apache
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 152%/5% 2 20 3 15m
➜ kubectl get hpa php-apache
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 88%/5% 2 20 6 18m
➜ kubectl get hpa php-apache
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 75%/5% 2 20 12 20m
La siguiente es una vista de la consola de AWS donde se ve como se han levantado instancias nuevas.
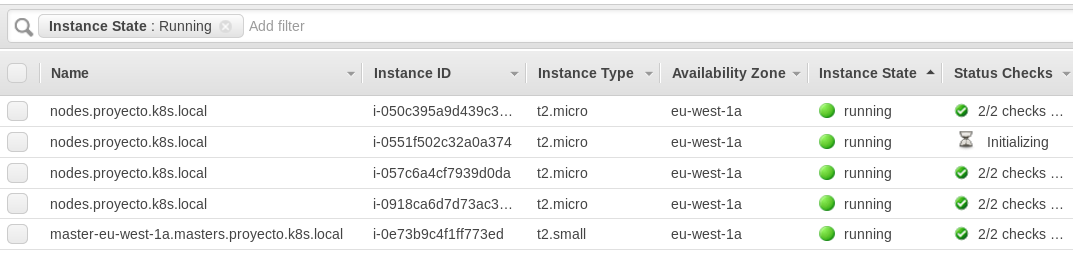
Figura 23 - Autoescalando Instancias Workers
Comprobar el log del pod de cluster auto-scaler
Comprobamos que sigue corriendo el pod como debe ser obvio si nuestro escenario esta escalando. Y pillamos el nombre del pod, para acto seguido visualizar la salida de su log:
kubectl get pods -n=kube-system
NAME READY STATUS RESTARTS AGE
cluster-autoscaler-1251066907-rf2sg 1/1 Running 0 27m
Y a continuación miramos dicho log y vemos como salta:
➜ kubectl logs cluster-autoscaler-1251066907-rf2sg -n=kube-system
I0611 22:32:15.145871 1 scale_up.go:193] Best option to resize: nodes.proyecto.k8s.local
I0611 22:32:15.145954 1 scale_up.go:197] Estimated 1 nodes needed in nodes.proyecto.k8s.local
I0611 22:32:15.173571 1 scale_up.go:286] Final scale-up plan: [{nodes.proyecto.k8s.local 2->3 (max: 4)}]
I0611 22:32:15.173686 1 scale_up.go:338] Scale-up: setting group nodes.proyecto.k8s.local size to 3
Y si volvemos a mirar los nodos:
➜ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-172-20-33-66.eu-west-1.compute.internal Ready node 38m v1.7.6
ip-172-20-34-101.eu-west-1.compute.internal Ready node 15m v1.7.6
ip-172-20-38-203.eu-west-1.compute.internal Ready node 38m v1.7.6
ip-172-20-48-222.eu-west-1.compute.internal Ready node 11m v1.7.6
ip-172-20-51-62.eu-west-1.compute.internal Ready master 39m v1.7.6
Parando la carga de trabajo
Si procedemos a parar el bucle y esperamos unos 15-20 minutos, vemos como automáticamente los nodos se destruyen y se va reduciendo el número de replicas:
➜ kubectl get hpa php-apache
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/5% 2 20 2 40m
Y el log:
➜ kubectl logs cluster-autoscaler-1251066907-rf2sg
I0611 23:04:00.873711 1 scale_down.go:594] Scale-down: removing empty node ip-172-20-48-222.eu-west-1.compute.internal
I0611 23:04:00.878599 1 factory.go:33] Event(v1.ObjectReference{Kind:"ConfigMap", Namespace:"kube-system", Name:"cluster-autoscaler-statu$
I0611 23:04:00.881200 1 factory.go:33] Event(v1.ObjectReference{Kind:"ConfigMap", Namespace:"kube-system", Name:"cluster-autoscaler-statu$
I0611 23:04:00.904849 1 delete.go:53] Successfully added toBeDeletedTaint on node ip-172-20-34-101.eu-west-1.compute.internal
I0611 23:04:00.905452 1 delete.go:53] Successfully added toBeDeletedTaint on node ip-172-20-48-222.eu-west-1.compute.internal
I0611 23:04:01.042645 1 aws_manager.go:186] Terminating EC2 instance: i-057c6a4cf7939d0da
Y finalmente se vuelve al estado mínimo que eran 2 instancias:
➜ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-172-20-33-66.eu-west-1.compute.internal Ready node 55m v1.7.6
ip-172-20-38-203.eu-west-1.compute.internal Ready node 55m v1.7.6
ip-172-20-51-62.eu-west-1.compute.internal Ready master 56m v1.7.6