Mantener el estado de nuestra aplicación
Si queremos mantener el estado de nuestra aplicación, frente a un fallo en las instancias, que por el motivo que fuera se cayerán dichas instancias. Y nos viéramos en la situación que automáticamente nuestros contenedores se vuelven a replicar a nuestro estado deseado, pero que ocurre si los datos de la aplicación se estaban almacenando dentro del propio contenedor por poner un ejemplo.¿No es mejor almacenar esos datos de manera replicada o en un servicio externo?
La opción de replicar el almacenamiento de forma local y replicándose en múltiples servidores es compleja de implementar para incluirla en este apartado.
Así que vamos a tirar por la opción de utilizar un servicio externo ya que estamos utilizando AWS, podemos elegir entre:
- S3
- Elastic File System (EFS)
- Elastic Block Store
La opción de S3 la descartamos ya que no vamos a sustituir el almacenamiento de un disco local, por llamadas a una API para poder almacenar los datos.
La segunda opción, EFS tiene una muy clara ventaja y es que puede montarse en múltiples instancias de EC2 repartidos en múltiples AZ. Y es lo más cercano a lo que tolerancia a fallos se refiere. Pero es muy costo y nos penalizaría en este caso la latencia.
Por lo tanto la última opción que nos queda es EBS donde el almacenamiento es mucho más rápido. La latencia de acceso a los datos sería muy baja. Pero tiene un pequeño inconveniente y es la disponibilidad. Este servicio no funciona en múltiples zonas de disponibilidad, si este fallara habría un tiempo de inactividad hasta que se restaurará dicha zona en caso de fallo.
Aún asi es la mejor opción que tenemos y más a la hora de utilizar en este caso Jenkis que dependerá mucho de I/O, y necesitamos que el acceso a los datos sea super ligero. Otra dos razones por la que decantarse por esta opción es la compatible con Kubernetes y que es mucho mas económico.
Como hemos comentado en el que caso de fallo en la AZ donde se encuentre el volumen, sería necesario migrar a otra zona saludable.
Así que vamos a introducirnos un poco en la creación de los volumenes en AWS con el servicio EBS:
Crear los volumenes en AWS
Lo primero que necesitamos saber es en que zona de disponibilidad se encuentran nuestros nodos workers, lo podemos conseguir de la siguiente forma:
➜ aws ec2 describe-instances \
| jq -r \
".Reservations[].Instances[] \
| select(.SecurityGroups[]\
.GroupName==\"nodes.$NAME\")\
.Placement.AvailabilityZone"
eu-west-1c
eu-west-1b
Nos deberán aparecer las dos AZ en las que se encuetran los nodos.
NOTA: puede causar confusión que ahora los nodos están en AZ's diferentes en comparación con apartados anteriores, esto se debe a que modifique el valor del InstanceGroup de los workers.
Vamos a almacenar las dos zonas de disponibilidad en un fichero y posteriormente seleccionar cada una de ellas y almacenarlas en una variable de entorno:
➜ aws ec2 describe-instances \
| jq -r \
".Reservations[].Instances[] \
| select(.SecurityGroups[]\
.GroupName==\"nodes.$NAME\")\
.Placement.AvailabilityZone" \
| tee zones
AZ_1=$(cat zones | head -n 1)
AZ_2=$(cat zones | tail -n 1)
Ahora vamos a proceder a crear los volumenes en las zonas de disponibilidad, por ejemplo, dos volumenes en una AZ y uno en otra. Tendrán un espacio de almacenamiento de 10GB, y serán del tipo gp2, por otro lado los etiquetaremos para que sea más fácil reconocerlos posteriormente:
➜ VOLUME_ID_1=$(aws ec2 create-volume \
--availability-zone $AZ_1 \
--size 10 \
--volume-type gp2 \
--tag-specifications "ResourceType=volume,Tags=[{Key=KubernetesCluster,Value=$NAME}]" \
| jq -r '.VolumeId')
➜ VOLUME_ID_2=$(aws ec2 create-volume \
--availability-zone $AZ_1 \
--size 10 \
--volume-type gp2 \
--tag-specifications "ResourceType=volume,Tags=[{Key=KubernetesCluster,Value=$NAME}]" \
| jq -r '.VolumeId')
➜ VOLUME_ID_3=$(aws ec2 create-volume \
--availability-zone $AZ_2 \
--size 10 \
--volume-type gp2 \
--tag-specifications "ResourceType=volume,Tags=[{Key=KubernetesCluster,Value=$NAME}]" \
| jq -r '.VolumeId')
Si por ejemplo miramos el valor de la variable de uno de ellos, debemos tener almacenado el id del volumen en AWS:
➜ echo $VOLUME_ID_1
vol-07b9ce41b602ada73
Por último si nos queremos asegurar de que se ha creado el volumen, podemos ejecutar la instrucción:
➜ aws ec2 describe-volumes \
--volume-ids $VOLUME_ID_1
{
"Volumes": [
{
"AvailabilityZone": "eu-west-1c",
"Attachments": [],
"Tags": [
{
"Value": "proyecto.k8s.local",
"Key": "KubernetesCluster"
}
],
"Encrypted": false,
"VolumeType": "gp2",
"VolumeId": "vol-07b9ce41b602ada73",
"State": "available",
"Iops": 100,
...
"Size": 10
}
]
}
Ahora que tenemos los volumenes disponibles en las mismas zonas de disponibilidad que las instancias EC2 workers, podemos proceder a crear los volumenes persistentes en Kubernetes.
En la siguiente figura podemos ver lo que acabamos de hacer:
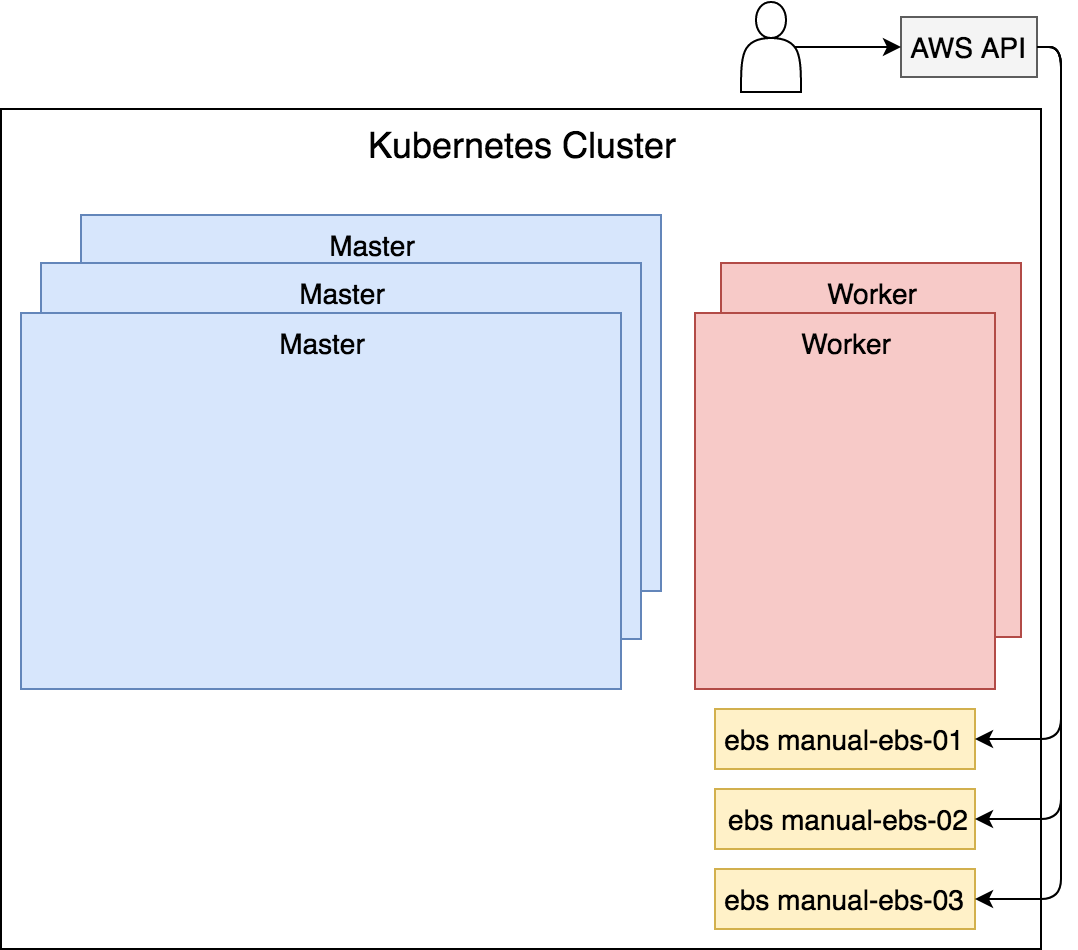
Figura 21 - Volumenes EBS creado en la misma zona que los workers
Volumenes Persistentes
El hecho de que tengamos los volumenes creado en EBS y disponibles, no significa que nuestro Clúster de Kubernetes sepa que estos existen. Para ello es necesario agregar los volumenes persistentes que actuan de puente entre el clúster de kubernetes y los volumenes creado con EBS.
Los volumenes persistentes son también recursos del clúster, pero su principal diferencia es que el ciclo de vida de estos es independiente de los Pods por los que estén siendo utilizados.
Dicho esto, vamos a crear la definición para dichos volumenes persistentes en formato YAML, aqui tenéis el pv.yml
kind: PersistentVolume
apiVersion: v1
metadata:
name: manual-ebs-01
labels:
type: ebs
spec:
storageClassName: manual-ebs
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
awsElasticBlockStore:
volumeID: REPLACE_ME_1
fsType: ext4
---
Echando un vistazo por encima, a las especificaciones del fichero vemos:
- storageClassName: en principio solamente para recordar el nombre de la clase de almacenamiento.
- storage capacity: pues indicamos un valor similar a la capacidad del volumen físico, sin sobre pasar el tamaño de este.
- accessModes: la manera en la que se monta el volumen, en este caso como lectura y escritura a la vez.
Por otro lado como sabemos que vamos a usar el servicio EBS de AWS, debemos indicar los siguientes valores:
- volumeID: donde indicamos el id del volumen.
- fsType: sistema de ficheros del volumen.
Ahora vamos a proceder a reemplazar los valores de los id de los volumenes y crear la definición dentro de nuestro clúster:
cat pv.yml \
| sed -e \
"s@REPLACE_ME_1@$VOLUME_ID_1@g" \
| sed -e \
"s@REPLACE_ME_2@$VOLUME_ID_2@g" \
| sed -e \
"s@REPLACE_ME_3@$VOLUME_ID_3@g" \
| kubectl create -f - \
--save-config --record
persistentvolume "manual-ebs-01" created
persistentvolume "manual-ebs-02" created
persistentvolume "manual-ebs-03" created
Ahora comprobamos que se encuentran los volumenes persistentes disponibles en nuestro clúster:
➜ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
manual-ebs-01 10Gi RWO Retain Available manual-ebs 1m
manual-ebs-02 10Gi RWO Retain Available manual-ebs 1m
manual-ebs-03 10Gi RWO Retain Available manual-ebs 1m
Bien ahora tenemos los volumenes creados en AWS y los volumenes persistentes creados en nuestro clúster disponibles, pero no están siendo utilizados. Hasta que alguién los reclame para su uso.
En la figura se refleja lo que hemos realizado en los pasos anteriores:
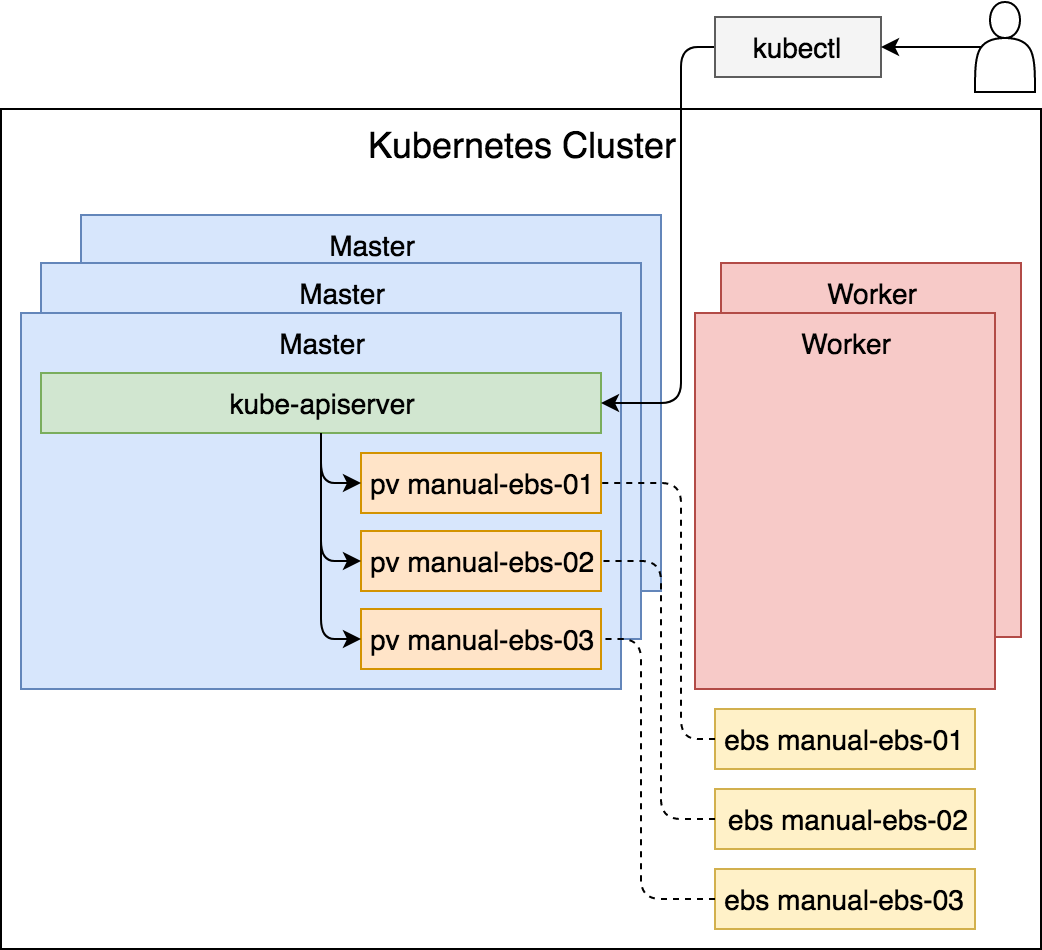
Figura 22 - Los volumenes persistentes asociados a los volumenes de EBS
En este proyecto no vamos a entrar en detalles de como se reclaman, pero básicamente habría que utilizar el recurso de PersistentVolumeClaim.