¿Qué es Kubernetes?, para abreviar solamente diré que es un sistema open source creado para la gestión de aplicaciones en contenedores o, dicho de otra forma, es un sistema de orquestación para contenedores. Permitiendo acciones como programar el despliegue, escalado o la monitorización de ellos, entre muchas otras más.
En internet hay mucha información sobre k8s ;).
¿Qué es KOPS?
Si visitas la página del proyecto de kops https://github.com/kubernetes/kops, lo primero que lees es que es la manera más fácil de poner en funcionamiento un cluster Kubernetes en producción. Según la opinión de algunos usuarios en internet y la mía es que esta frase es cierta, siempre y cuando se excluya Google Kubernetes Engine (GKE).
A fecha de la redacción de este documento (Mayo de 2018), otros proveedores de hosting todavía no han publicado su solución Kubernetes-as-a-service. El servicio Elastic Container de Amazon para Kubernetes (EKS) aún no está abierto al público.
Actualización (Junio de 2018) El servicio EKS se encuentra disponible, pero solamente en las regiones de N. Virginia y Oregon.
El servicio Azure Container es también otra opción, que está disponible desde 2015 pero según he leído tiene algunos puntos débiles. Por lo tanto, sigo pensando que kops es la mejor manera de conseguir tener funcionando kubernetes en producción. Ya que tiene casi el mismo nivel de complejidad, pero sin perder el control de lo que queremos y cómo lo queremos en cada momento. Nos permite ajustar más el cluster a nuestra necesidad de lo que nos sería posible con soluciones incluidas en el hosting. Es completamente de código abierto, puede almacenarse en control de versiones y no está diseñado para encerrarse en un proveedor de hosting.
Así que en el caso de que nuestro proveedor de hosting sea AWS, kops es la mejor opción para crear un cluster de kubernetes. Si es cierto que GKE funciona también muy bien y esto daría para un debate bastante largo.
Se espera que kops se extienda a otros proveedores. Si no me equivoco VMWare está en Alfa o podría estar ya estable y se ha añadido soporte para Azure y Digital Ocean.
Kops nos permite crear un clúster de Kubernetes de producción. Lo que quiere decir que no solo podemos para crear el cluster en sí, sino también podemos actualizarlo sin necesidad de que exista inactividad en ningún momento o eliminarlo si ya no va hacer necesario. Un clúster no se puede denominar “production grade” a menos que este se encuentre en alta disponibilidad y tolerante a fallos.
Deberíamos de poder ejecutar todo esto desde una línea de comandos si quisiéramos automatizarlo. Esto y otras cosas más hacen de kops una herramienta excelente para este fin. Kops sigue la misma filosofía que Kubernetes, donde creamos un conjunto de objetos JSON o YAML que se enviarán a los controladores y estos crean el clúster.
Más adelante detallaremos lo que Kops puede y no puede hacer. De momento en el próximo apartado veremos los requisitos previos para la instalación del clúster.
Configurando AWS
Llegados a este punto debo de suponer que se dispone de una cuenta en AWS, si no es así, lo primero que debemos hacer es registrarnos en Amazon Web Services.
Posteriormente necesitamos conseguir nuestras credenciales de AWS, para ello si ya nos hemos registrado, abrimos la consola de Amazon EC2 y hacemos clic en el menú de la parte superior derecha de la página:
Figura 8 - Mis credenciales de seguridad
Nos aparecerá una ventana emergente que nos informa de que estamos accediendo a la página donde podemos administrar las credenciales de seguridad de de nuestra cuenta de AWS:
Figura 9 - Aviso
En la siguiente ventana veremos los diferentes tipos de credenciales:

Figura 10 - Claves de acceso
Expandimos la sección que se denomina “Access keys (access key ID and secret access key)” y hacemos clic en el botón “Crear nueva clave de acceso”:
Figura 11 - Crear nueva clave de acceso
Automáticamente después de pulsar el botón, se nos creará la clave de acceso nueva, importante anotar la “Secret Access Key” ya que no es posible visualizarla nuevamente después, por otro lado, descargar la clave debido a que AWS tampoco nos ofrece la posibilidad de descargarlo en otro momento.
Figura 12 - Clave creada con éxito
Al hacer clic en “Download key file”, se nos descarga un fichero con extensión .csv que contiene tanto nuestro Access Key ID como la Secret Access Key.
IMPORTANTE: POR SEGURIDAD ES ALTAMENTE RECOMENDABLE ALMACENAR ESTE FICHERO EN UN SITIO SEGURO CON LOS PERMISOS ADECUADOS Y NO COMPARTIRLO CON NADIE.
El siguiente paso es colocar las claves en variables de entorno que serán usadas por la interfaz de línea de comando de AWS.
export AWS_ACCESS_KEY_ID=AKIAJUMCPSYBTOBWKBWQ
export AWS_SECRET_ACCESS_KEY=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
Ahora es necesario instalar AWS CLI y recopilar alguna información sobre tu cuenta. En linux es necesario tener python como mínimo la versión 2.6.5 e instalar con pip:
pip install aws-cli --upgrade --user
Una vez hecho lo anterior, podemos confirmar que la instalación fue satisfactoria al mostrar como salida la versión:
aws --version
En mi portátil la salida es la siguiente:
aws-cli/1.15.16 Python/2.7.13 Linux/4.9.0-3-amd64 botocore/1.10.16
Amazon EC2 está alojada en múltiples ubicaciones en todo el mundo. Estas ubicaciones están compuestas por regiones y zonas de disponibilidad. Cada región es un área geográfica separada, compuesta de múltiples ubicaciones aisladas conocidas como zonas de disponibilidad.
Amazon EC2 nos proporciona la capacidad de colocar recursos, como instancias y datos en múltiples ubicaciones.
Así que es necesario definir la variable de entorno AWS_DEFAULT_REGION que se encarga de decirle a AWS CLI que región nos gustaría que se use por defecto.
export AWS_DEFAULT_REGION=eu-west-1
Es posible cambiar el valor de la variable a cualquier región, o por lo menos que tenga tres zonas de disponibilidad. Más adelante se discutirá las razones por las que se usará la región eu-west-1 y la necesidad de tener varias zonas de disponibilidad.
A continuación, vamos a crear algunos recursos de Gestión de identidades y accesos (IAM). Aunque se pueda crear el clúster con el usuario que utilizamos para registrarnos en AWS, es una buena práctica crear una cuenta a parte que contenga solo los privilegios necesarios para ejecutar las siguientes instrucciones.
Primero, vamos a crear un grupo IAM llamado kops:
# aws iam create-group --group-name kops
{
"Group": {
"GroupName": "kops",
"Path": "/",
"Arn": "arn:aws:iam::826764960316:group/kops",
"CreateDate": "2018-04-26T21:22:36.386Z",
"GroupId": "AGPAJ4GHUTOAPSH2JASRC"}
}
La información que devuelve el resultado no es de mucha importancia, a excepción de ver que no contiene ningún mensaje de error y la confirmación de que el grupo se creó con éxito.
A continuación, asignaremos algunas políticas al grupo creado, proporcionando así a los futuros usuarios que se agreguen a dicho grupo los permisos suficientes para crear los objetos que necesitaremos.
Desde que el clúster básicamente consiste en instancias de EC2, el grupo necesitará permisos para poder crearlas y administrarlas. Por otro lado, necesitaremos un lugar para almacenar el estado del clúster, necesitando así acceso al servicio S3 de Amazon.
Además, necesitamos agregar permisos del servicio VPC para que kops pueda configurar la red del clúster. Finalmente necesitaremos también poder crear IAM adicionales.
En AWS, los permisos de usuario se otorgan mediante la creación de políticas. Necesitaremos las siguientes:
- AmazonEC2FullAccess
- AmazonS3FullAccess
- AmazonVPCFullAccess
- IAMFullAccess
Los siguientes comandos adjuntos, asocian las diferentes políticas al grupo kops:
aws iam attach-group-policy --group-name kops \
--policy-arn arn:aws:iam::aws:policy/AmazonEC2FullAccess
aws iam attach-group-policy --group-name kops \
--policy-arn arn:aws:iam::aws:policy/AmazonS3FullAccess
aws iam attach-group-policy --group-name kops \
--policy-arn arn:aws:iam::aws:policy/AmazonVPCFullAccess
aws iam attach-group-policy --group-name kops \
--policy-arn arn:aws:iam::aws:policy/IAMFullAccess
Una vez tenemos el grupo con los permisos suficientes, podemos crear el nuevo usuario que se añadirá a este:
# aws iam create-user --user-name kopsuser
{
"User": {
"UserName": "kopsuser",
"UserId": "AIDAJUSIR5SBAPPN76LOS",
"CreateDate": "2018-05-09T09:10:27.272Z",
"Path": "/",
"Arn": "arn:aws:iam::826764960316:user/kopsuser"
}
}
Ahora sí, añadimos a dicho usuario al grupo kops:
aws iam add-user-to-group --user-name kopsuser --group-name kops
Finalmente, necesitaremos unas claves de acceso para el nuevo usuario que hemos creado. Sin ellas, no podríamos actuar el nombre de dicho usuario:
aws iam create-access-key \
--user-name kopsuser > kopsuser-credentials
Las claves de acceso se han creado y almacenado en el fichero con el nombre que le hemos indicado “kops-credentials”. Si echamos un vistazo al contenido del fichero:
cat kopsuser-credentials
{
"AccessKey": {
"SecretAccessKey": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXS5os",
"UserName": "kopsuser",
"CreateDate": "2018-05-09T09:17:45.531Z",
"Status": "Active",
"AccessKeyId": "XXXXXXXXXXXXXXXX5CQ"
}
}
Ahora necesitamos tomar el valor de las entradas SecretAccessKey y AccessKeyId. El siguiente paso es parsear el contenido del fichero kopsuser-credentials y almacenar los dos valores como variables de entorno AWS_ACCESS_KEY_ID y AWS_SECRET_ACCESS_KEY.
Para automatizar aún más vamos hacer uso de jq para parsear el contenido json del fichero.
Desde el enlace podemos descargar el código fuente para linux, OS X, Windows u otras plataformas. En mi caso voy a instalarlo desde la paquetería oficial de Debian Stretch:
apt update
apt install jq
Versión utilizada:
# jq -version
jq-1.5-1-a5b5cbe
Procedemos a exportar ambos valores:
export AWS_ACCESS_KEY_ID=$(\
cat kops-credentials | jq -r \
'.AccessKey.AccessKeyId')
export AWS_SECRET_ACCESS_KEY=$(
cat kops-credentials | jq -r \
'.AccessKey.SecretAccessKey')
NOTA: hemos utilizado el comando cat para mostrar el contenido del fichero, combinado con jq para filtrar la entrada solo del campo que hemos indicado.
A partir de ahora todos los comandos de AWS CLI no serán ejecutados con el usuario administrador de nuestra cuenta, si no con el nuevo usuario que hemos registrado denominado kopsuser.
El siguiente paso será decidir qué zonas de disponibilidad vamos a usar, para ello podemos ver las zonas disponibles dentro de la región que hemos pasado por la variable, en este caso eu-west-1.
aws ec2 describe-availability-zones
--region $AWS_DEFAULT_REGION
{
"AvailabilityZones": [
{
"State": "available",
"ZoneName": "eu-west-1a",
"Messages": [],
"RegionName": "eu-west-1"
},
{
"State": "available",
"ZoneName": "eu-west-1b",
"Messages": [],
"RegionName": "eu-west-1"
},
{
"State": "available",
"ZoneName": "eu-west-1c",
"Messages": [],
"RegionName": "eu-west-1"
}
]
}
Como podemos ver existen tres zonas de disponibilidad, que vamos a almacenarlas en una variable de entorno:
export ZONES=$(aws ec2 \
describe-availability-zones \
--region $AWS_DEFAULT_REGION \
| jq -r \
'.AvailabilityZones[].ZoneName' \
| tr '\n' ',' | tr -d ' ')
ZONES=${ZONES%?}
echo $ZONES
Al igual que con las variables de entorno anteriores, usamos jq para limitar el resultado solamente a los nombres de las zonas, y combinamos eso con tr para reemplazar los saltos de línea con comas. La siguiente instrucción elimina la coma al final de la lista.
Para empezar a crear el cluster, es crear un par de claves para hacer la conexión SSH y acceder a las instancias EC2. Vamos a crear un directorio dedicado para la creación del cluster.
mkdir -p cluster
cd cluster
Creamos las claves SSH con el comando aws ec2:
aws ec2 create-key-pair \
--key-name proyecto \
| jq -r '.KeyMaterial' \
>proyecto.pem
Hemos creado el par de claves nuevo, filtrando la salida solamente con el campo KeyMaterial, y almacenandolo en un fichero llamado proyecto.pem.
Por razones de seguridad cambiamos los permisos del fichero para que solo pueda ser leído por el usuario actual:
chmod 400 proyecto.pem
Finalmente, solo necesitamos el segmento público de las claves generada, para extraer dicha parte usaremos ssh-keygen:
ssh-keygen -y -f proyecto.pem \
>proyecto.pub
Aspectos a tener en cuenta
Llegados a este punto estamos listos para crear un clúster, pero vamos a estudiar los aspectos a tener en cuenta según nuestro escenario.
Las siguientes elecciones son importantes ya que de no elegir la correcta, podría impedirnos a la hora de lograr los objetivos que podamos tener.
La primera pregunta que se puede realizar es, ¿queremos tener alta disponibilidad? A priori lo lógico es decir que sí y sería extraño si alguien respondiera que no. En cambio nos preguntaremos qué cosas pueden hacer que nuestro clúster disminuya.
Número de nodo masters
Cuando un nodo es destruido, Kubernetes reprograma todas las aplicaciones que se están ejecutando dentro de los nodos “sanos”. Todo lo que habría que hacer es crear un nuevo servidor y añadirlo al cluster, consiguiendo así que la capacidad vuelva a los valores deseados.
Aún así esto sería crítico si el servidor que falló era el único master, no habría clúster al que poder añadir más servidores. Ya que estos son los que alojan los componentes críticos sin los cuales Kubernetes no podría operar.
Y entonces ¿bastaría con tener dos masters? pues parece ser que no, que a pesar de que si uno fallará, existiera todavía un nodo master, el cluster no funcionaría.
Cada información que ingresa en un nodo master, se debe propagar a los demás masters existentes, y sólo después de que se haya establecido la mayoría, se confirma esa información.
Por lo tanto en el caso de existir solo 2 nodo masters, si perdiéramos la mayoría (50%+1), los nodos masters no podrían llegar a un “acuerdo” y no podrían operar. Si falla uno de los dos nodos podemos obtener solamente la mitad de votos. Siendo así necesario tener mínimo tres nodos master o más.
Los números impares mayores que uno son números “mágicos”. Si no vamos a crear un gran cluster nos valdría con tres nodo master solamente, para echar a funcionar el clúster.
Con tres nodos maestros, estamos a salvo de un fallo proveniente de alguno de ellos. Ya que los servidores que fallen serán reemplazados por otros nuevos, siempre que falle solamente un nodo maestro a la vez, antes de poder ser sustituido, podríamos decir que nuestro cluster es tolerante a fallos y está en alta disponibilidad.
Todo en un mismo CPD..
Otra lógica a tener en cuenta es, ¿de qué vale tener múltiples nodos maestros, si se encuentran todos en el mismo centro de datos y este último se cae?.
Es imposible garantizar que un centro de datos no va a sufrir una interrupción de algún tipo nunca. Entonces, necesitamos más de un centro de datos. Siguiendo con la lógica anterior sabes que necesitamos al menos tener tres nodos masters. Pero, resulta casi imposible tener tres o más centros de datos. Si estos están demasiado separados, la latencia entre ellos podría ser demasiado alta. Dado que cada información se propaga a todos los nodos maestros dentro del clúster, la lenta comunicación entre los centros de datos supondría un impacto severo en el cluster.
Por lo tanto necesitamos tres centros de datos que estén lo suficientemente cerca para proporcionar una latencia baja, pero sin embargo, físicamente separados, de modo que si falla uno, no afecte a los demás. Como estamos a punto de crear el clúster en AWS, tenemos la posibilidad de utilizar las zonas de disponibilidad (AZ) que son centros de datos separados físicamente con una latencia muy baja entre ellos.
Red
¿Qué red debemos usar?. Podemos elegir entre kubenet, CNI, clásica y redes externas. La red clásica nativa de Kubernetes está “obsoleta” siendo esto un punto a favor de kubenet, por lo que podemos descartarla directamente.
Las redes externas se usa en algunas implementaciones personalizadas y solo para casos particulares.
Quedando así las opciones de kubenet y CNI.
Container Network Interface (CNI) nos permite conectar un controlador de red de terceros. Kops admite redes como Calico, flannel, Canal (Flannel + Calico), kopeio-vxlan, kube-router, romana, weave, amazon-vpc-routed-eni. Cada una de esas redes tiene pros y contras y difiere en su implementación y objetivos principales. Elegir entre ellos requeriría de un análisis detallado de cada uno. Así que vamos a enfocarnos en kubenet.
Kubenet es la solución de red predeterminada de kops. Es una red nativa de Kubernetes, y se considera una solución fiable y estable. Sin embargo, viene con una limitación. En AWS, las rutas para cada nodo se configuran en tablas de enrutamiento de AWS VPC. Como esas tablas no pueden tener más de cincuenta entradas, kubenet se puede usar en clústeres con hasta cincuenta nodos. Si se planea tener un clúster más grande que esto, habrá que cambiar a uno de los CNI mencionados anteriormente.
Lo bueno en definitiva es que utilizar cualquiera de las soluciones de red es fácil. Y lo único que hay que hacer es especificar el argumento –networking seguido del nombre de la red.
Para decidir cual es el mejor habría que hacer como hemos dicho antes un estudio más amplio, así que para el cluster que se va a crear, vamos a utilizar la solución de kops predetermina kubenet.
Tamaño de los nodos del cluster
El último aspecto a tener en cuenta, es elegir el tamaño que necesitamos para nuestros nodos. En este caso si no ejecutamos muchas aplicaciones, nos valdría con utilizar las t2.small y así mantenemos los gastos mínimo en relación calidad/precio. Las t2.micro son demasiado pequeñas para manejar toda la información, así que el siguiente tipo de instancia EC2 más pequeñas entre las disponibles de AWS, son las t2.small.
Creación del Clúster
Para empezar, es necesario decidir un nombre para el cluster. Por ejemplo proyecto.k8s.local. La última parte (.k8s.local) es obligatoria si no disponemos de un DNS a mano. Kops utiliza este nombre de forma convencional ya que se basa en gossip para descubrir a los nodos dentro del cluster, digamos que hace el proceso de DNS de manera gratuita y mucho más simple.
Vamos almacenar el nombre en una variable de entorno para poder acceder a él más fácilmente en un futuro.
export NAME=proyecto.k8s.local
Como hemos dicho es necesario almacenar el estado en algún lugar, en AWS la única opción a día de hoy para almacenar dicha información son los buckets de Amazon S3. Asignamos un nombre para el bucket en una variable de entorno:
export BUCKET_NAME=proyecto-$(date +%s)
Para crear el bucket en AWS, utilizamos la siguiente instrucción:
aws s3api create-bucket \
--bucket $BUCKET_NAME \
--create-bucket-configuration \
LocationConstraint=$AWS_DEFAULT_REGION
{
"Location": "http://proyecto-1527665818.s3.amazonaws.com/"
}
Ahora por comodidad, definiremos otra variable de entorno KOPS_STATE_STORE. Que usaremos para indicar el bucket dónde vamos a guardar el estado.
export KOPS_STATE_STORE=s3://$BUCKET_NAME
Ahora nos falta, tener instalado kops. En mi caso como usuario linux, sería de la siguiente forma:
curl -LO https://github.com/kubernetes/kops/releases/download/$(curl -s
https://api.github.com/repos/kubernetes/kops/releases/latest | grep tag_name | cut -d '"' -f
4)/kops-linux-amd64
chmod +x kops-linux-amd64
sudo mv kops-linux-amd64 /usr/local/bin/kop
El comando para crear el cluster usando las especificaciones que han sido discutidas anteriormente:
kops create cluster \
--name $NAME \
--master-count 3 \
--node-count 1 \
--node-size t2.small \
--master-size t2.small \
--zones $ZONES \
--master-zones $ZONES \
--ssh-public-key proyecto.pub \
--networking kubenet \
--kubernetes-version v1.8.4 \
--authorization RBAC \
--yes
Hemos especificado que el cluster debe tener tres nodo masters y un nodo worker. Podemos siempre incrementar el número de workers, pero no es necesario empezar con más de los que necesitamos en este momento.
El tamaño de los nodos son t2.small. Y ambos tipos de nodos se extenderán a través de las tres zonas de disponibilidad que le especificamos desde la variable de entorno $ZONES. Más adelante hemos definido la clave pública y el tipo de red.
Con el argumento –kubernetes-version podemos ejecutar la versión que queremos de kubernetes exactamente. Si no indicamos este argumento, obtendremos la última versión considerada estable por kops.
Por defecto si no se especifica el argumento –authorization el valor que coge es AlwaysAllow. Como intentamos simular un cluster en producción utilizaremos el valor RBAC.
El argumento –yes especifica que el clúster debe crearse inmediatamente. Si no lo especificamos, kops solo actualizará el estado en el bucket S3. Y nos faltaría ejecutar kops apply para crear el clúster en dos pasos. Esto dependerá de lo impaciente que seamos.
La salida del comando anterior debe ser parecida a esto:
Cluster is starting.
It should be ready in a few minutes.
Suggestions:
* validate cluster: kops validate cluster
* list nodes: kubectl get nodes --show-labels
* ssh to the master: ssh -i ~/.ssh/id_rsa admin@api.proyecto.k8s.local
* the admin user is specific to Debian. If not using Debian please use the appropriate user
based on your OS.
* read about installing addons at:
https://github.com/kubernetes/kops/blob/master/docs/addons.md.
Se puede ver como el nuevo contexto de kubectl es ahora el nombre de nuestro cluster y aparece una serie de sugerencias a realizar después de que finalice la creación del cluster.
Ahora con kops podemos capturar la información sobre el nuevo cluster que hemos creado:
kops get cluster
NAME CLOUD ZONES
proyecto.k8s.local aws eu-west-1a,eu-west-1b,eu-west-1c
Esta última información nos dice bien poco, ya que nos informa de algo que ya sabíamos como el nombre de el cluster y las zonas en las que está corriendo.
Para obtener más información sobre el cluster en sí vamos a instalar la herramienta kubectl.
Para Debian/Ubuntu bastaría con las siguientes instrucciones:
apt-get update && apt-get install -y apt-transport-https
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb http://apt.kubernetes.io/ kubernetes-xenial main
EOF
apt-get update
apt-get install -y kubectl
Ahora si ejecutamos:
kubectl cluster-info
Kubernetes master is running at https://api-proyecto-k8s-local-oiqnes-1891537701.eu-west-1.elb.amazonaws.com
KubeDNS is running at https://api-proyecto-k8s-local-oiqnes-1891537701.eu-west-1.elb.amazonaws.com/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
En esta salida si podemos ver como tanto el master como KubeDNS estan corriendo. Lo que significa probablemente que el cluster esté listo. Si no apareciera KubeDNS habría que esperar posiblemente unos minutos más.
Podemos obtener información más detalla sobre el cluster a través del comando:
kops validate cluster
Using cluster from kubectl context: proyecto.k8s.local
Validating cluster proyecto.k8s.local
INSTANCE GROUPS
NAME ROLE MACHINETYPE MIN MAX SUBNETS
master-eu-west-1a Master t2.small 1 1 eu-west-1a
master-eu-west-1b Master t2.small 1 1 eu-west-1b
master-eu-west-1c Master t2.small 1 1 eu-west-1c
nodes Node t2.small 1 1 eu-west-1a,eu-west-1b,eu-west-1c
NODE STATUS
NAME ROLE READY
ip-172-20-107-95.eu-west-1.compute.internal master True
ip-172-20-41-196.eu-west-1.compute.internal node True
ip-172-20-51-240.eu-west-1.compute.internal master True
ip-172-20-91-5.eu-west-1.compute.internal master True
Your cluster proyecto.k8s.local is ready
Esta salida parece ser más útil, y podemos ver como se ha formado el cluster por las 4 instancias, los 3 nodos maestros y el nodo worker. Más concretamente según los términos de AWS. Tenemos un auto- scaling group por cada nodo master y otro para todos los nodos workers que existan.
La causa por la que cada nodo master se encuentre solo en un auto-scaling group es la manera de garantizar que cada uno se ejecuta en su propia zona de disponibilidad. Garantizando así que si existe un fallo en la zona de disponibilidad no afecte solo a un nodo master. Los nodos workers no están restringidos a un AZ específico. AWS colocará los nodos en cualquier AZ que esté disponible al azar.
En la siguiente imagen podemos ver la estructura que acabamos de comentar:
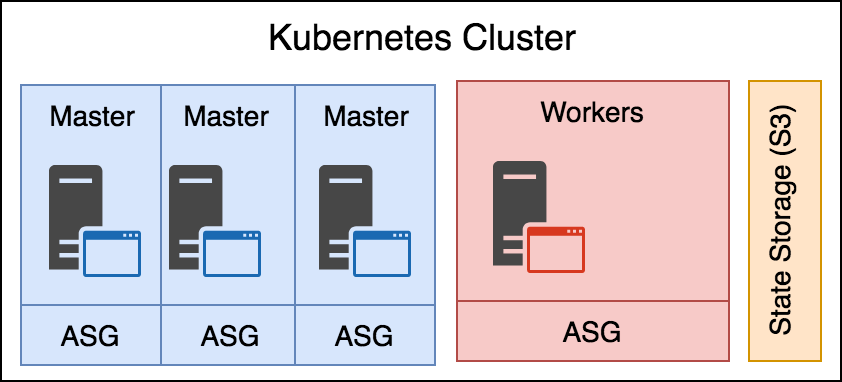
Figura 13 - Estructura del Clúster
Realmente hay muchos más componentes de los que se muestran en la imagen, así que intentaremos desglosarlos uno a uno cada uno de los componentes que ha creado kops por nosotros.
Componentes del Clúster
Cuando kops ha creado las máquinas virtuales (EC2), lo primero que ejecutó fue nodeup. Esto lo que hizó fue instalar unos pocos de paquetes, asegurando que los servicios de Docker, Kubelet y Protokube estuvieran levantados y corriendo dentro de cada uno de los nodos.
- Docker como ya sabemos es el servicio que se encarga de correr los contenedores dentro de los nodos.
- Kubelet es el agente que va instalado en cada uno de los nodos, donde su tarea principal es ejecutar Pods. O para ser más concretos, garantizar que los contenedores descritos en PodSpecs se estén ejecutando mientras estén “sanos”. Principalmente la información sobre los pods la obtiene de la API del servidor de Kubernetes o como alternativa puede obtener también la información a través de ficheros o endpoints HTTP.
- Protokube a diferencia de Docker y Kubelet, es específico para kops. Sus principales responsabilidades son: descubrir los discos maestros, montarlos y crear manifests. Algunos de esos manifests son utilizados por Kubelet para crear Pods a nivel de sistema y para asegurar que estén siempre corriendo.
Además, cuando los contenedores que son definidos a través de Pods vía manifest (creado por Protokube) son arrancados, Kubelet también intenta contactar con la API del servidor que, finalmente, también es iniciada por él, una vez la conexión es establecida, Kubelet registra el nodo donde este se encuentre corriendo.
Estos tres paquetes estan corriendo en todos los nodos, sin importar que sean masters o workers.
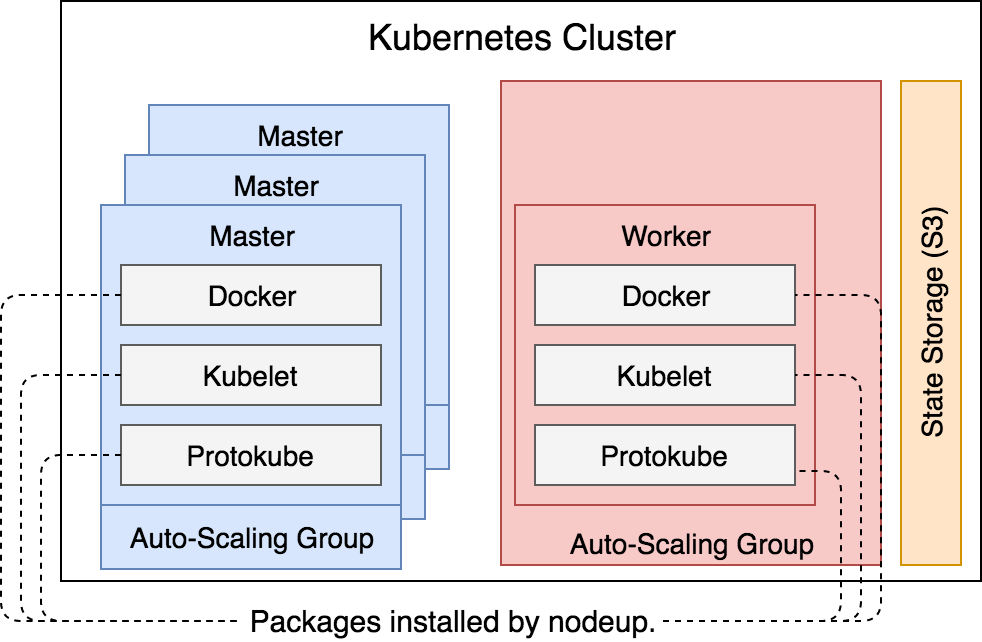
Figura 14 - Los servicios instalados dentro de los nodos
Si echamos un vistazo los Pods que están corriendo a nivel de sistema en nuestro cluster:
# kubectl --namespace kube-system get pods
NAME READY STATUS RESTARTS AGE
dns-controller-6b689bc66f-rl5d2 1/1 Running 0 13m
etcd-server-events-ip-172-20-107-95.eu-west-1.compute.internal 1/1 Running 0 13m
etcd-server-events-ip-172-20-51-240.eu-west-1.compute.internal 1/1 Running 0 14m
etcd-server-events-ip-172-20-91-5.eu-west-1.compute.internal 1/1 Running 0 13m
etcd-server-ip-172-20-107-95.eu-west-1.compute.internal 1/1 Running 0 13m
etcd-server-ip-172-20-51-240.eu-west-1.compute.internal 1/1 Running 0 13m
etcd-server-ip-172-20-91-5.eu-west-1.compute.internal 1/1 Running 0 13m
kube-apiserver-ip-172-20-107-95.eu-west-1.compute.internal 1/1 Running 1 13m
kube-apiserver-ip-172-20-51-240.eu-west-1.compute.internal 1/1 Running 0 13m
kube-apiserver-ip-172-20-91-5.eu-west-1.compute.internal 1/1 Running 0 14m
kube-controller-manager-ip-172-20-107-95.eu-west-1.compute.internal 1/1 Running 0 13m
kube-controller-manager-ip-172-20-51-240.eu-west-1.compute.internal 1/1 Running 0 13m
kube-controller-manager-ip-172-20-91-5.eu-west-1.compute.internal 1/1 Running 0 13m
kube-dns-6c4cb66dfb-6fwns 3/3 Running 0 13m
kube-dns-6c4cb66dfb-whngt 3/3 Running 0 13m
kube-dns-autoscaler-f4c47db64-6jdvf 1/1 Running 0 13m
kube-proxy-ip-172-20-107-95.eu-west-1.compute.internal 1/1 Running 0 13m
kube-proxy-ip-172-20-41-196.eu-west-1.compute.internal 1/1 Running 0 12m
kube-proxy-ip-172-20-51-240.eu-west-1.compute.internal 1/1 Running 0 14m
kube-proxy-ip-172-20-91-5.eu-west-1.compute.internal 1/1 Running 0 14m
kube-scheduler-ip-172-20-107-95.eu-west-1.compute.internal 1/1 Running 0 13m
kube-scheduler-ip-172-20-51-240.eu-west-1.compute.internal 1/1 Running 0 14m
kube-scheduler-ip-172-20-91-5.eu-west-1.compute.internal 1/1 Running 0 13m
Si nos fijamos más detenidamente hay varios componentes del core que están corriendo. Podemos dividir los componentes del core en dos grupos, los componentes master que solo corren en los nodos masters que serían:
- kube-apiserver
- kube-controller-manager
- kube-scheduler
- etcd
- dns-controller
Por otro lado, los componentes del nodo se ejecutan en todos los nodos, tanto en masters como en workers. Además de Docker, Kubelet y Protokube como citamos anteriormente, tenemos al componente “kube-proxy”. A continuación se explican brevemente los nuevos componentes nombrados:
Kubernetes API Server (kube-apiserver)
Es el encargado de aceptar las solicitudes para crear,actualizar o eliminar recursos de Kubernetes. Este componente escucha en los puertos tcp 8080 y 443. Al primer puerto se accede de forma insegura, ya que se accede a él a través del propio servidor. A través de él, el resto de componentes pueden registrarse ellos mismos sin requerir un token. El puerto 443 se utiliza para todas las comunicaciones externas con la API del servidor, como por ejemplo, cuando ejecutamos como usuario un comando kubectl. Incluso el propio componente Kubelet utiliza este puerto para llegar a la API del servidor y registrarse así como un nodo.
No importa quien inicie realmente la comunicación con la API del servidor, su propósito es validar y configurar el objeto de la API. Que entre otros, pueden ser Pods, Services, ReplicaSets u otros. El uso de esta API no se limita a las interacciones con el usuario. Todos los componentes del cluster interactúan con la API del servidor para operaciones que requieran un “estado compartido” en todo el cluster.
El estado compartido y todos los datos del clúster son almacenados en etcd. El almacenamiento de los datos se guardan en el formato clave/valor, y se encuentran altamente disponibles a través de la replicación de datos consistente. Esto se divide dentro de dos Pods, donde etcd-server mantiene el estado del cluster y etcd-server-events almacena los eventos que ocurren dentro de él.
Nota: Kops automáticamente crea volumenes en AWS para almacenar esta información de etcd.
Kubernetes Controller Manager (kube-controller-manager)
Es el encargado de ejecutar los controladores, como:
- ReplicaSets
- Deployments
Además de los controladores de objetos como estos anteriores, kube-controller-manager debe controlar los controladores del nodo responsables de monitorizar los servidores y responder cuando uno deja de estar disponible.
Kubernetes Scheduler (kube-scheduler)
Mira la api del servidor para nuevos Pods y los asigna a un nodo en concreto. A partir de ahí, esos Pods son ya gestionados por el kubelet de dicho nodo asignado.
DNS Controller (dns-controller)
Permite que los nodos y usuarios sean capaces de encontrar la API del servidor.
Kubernetes Proxy (kube-proxy)
Refleja los servicios definidos a través de la API del servidor. Está a cargo del reenvio de trafíco a través del protocolo TCP y UDP. Este componente corre en todos los nodos del cluster, tanto masters como workers.
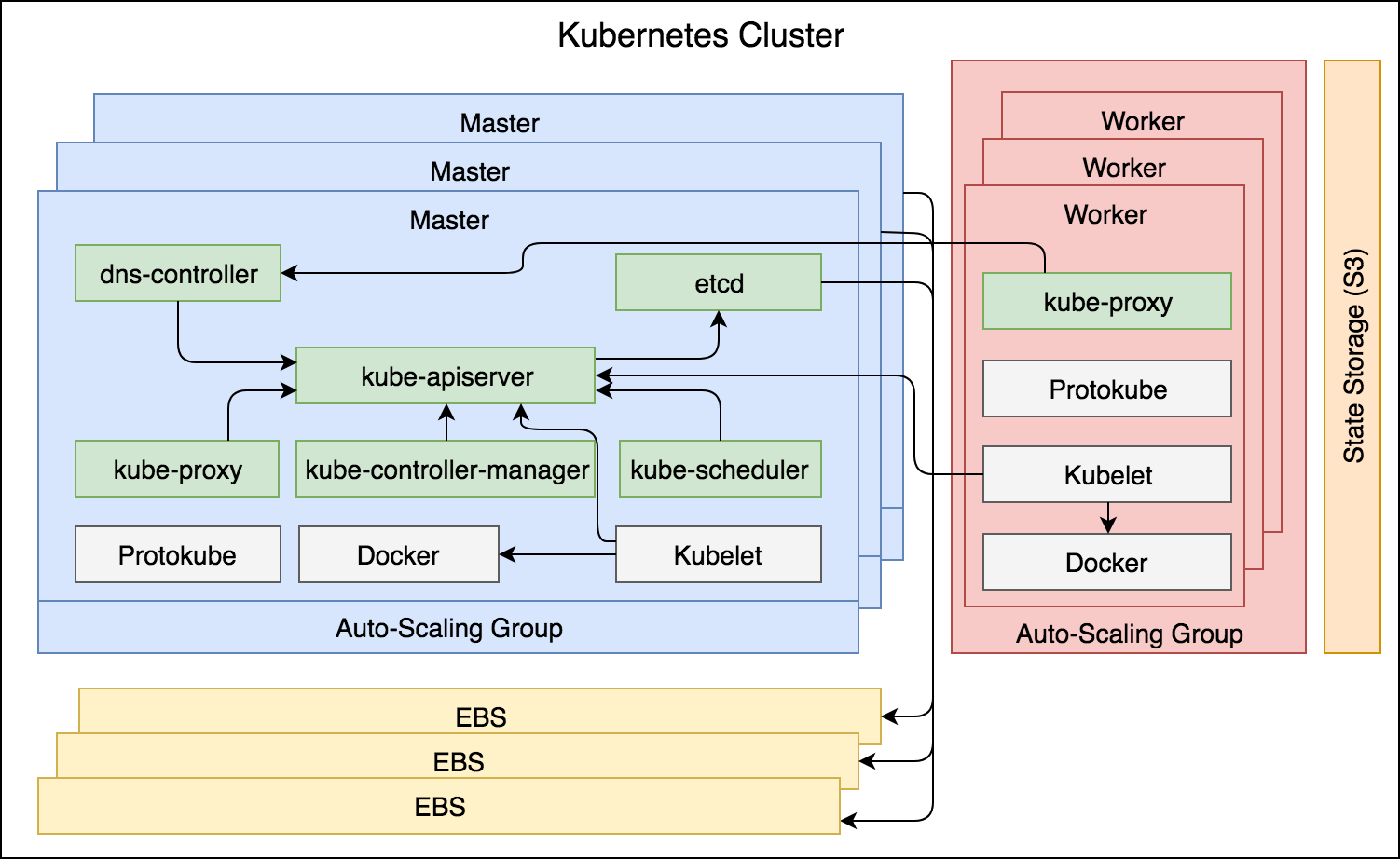
Figura 15 - Los componentes principales del Clúster
Lo siguiente que vamos a ver, será actualizar nuestro clúster.
Actualizando el Instance Group
Por mucho que planteemos y analicemos e intentemos precedir un estado perfecto para nuestro cluster, puede ser que la configuración que hayamos hecho sea ideal para un momento determinado, pero no nos sirva para el día de mañana. Las cosas van cambiando y necesitamos adaptarnos al cambio. Es por eso que nuestro cluster debería ser capaz de aumentar y disminuir su capacidad de forma automática medíante la evaluación de métricas o algún tipo de alerta que interactue o bien directamente con kops o con la api de AWS.
Aún así de momento vamos a limitarnos a actualizar nuestro clúster de forma manual.
Con Kops, no podemos actulizar el cluster directamente. En su lugar, editamos el estado deseado del cluster que se encuentra almacenado en el S3 Bucket. Una vez se cambie el estado, kops hará los cambios necesarios para cumplir con el nuevo estado deseado. Así que para ver un ejemplo, vamos a actualizar nuestro cluster, para que la cantidad de nodos workers aumente de uno a dos. Vamos a agregar una instancia más al Clúster.
Así como primera toma, vamos a ver los sub commandos que nos proporciona la ayuda de kops edit:
kops edit --help
Available Commands:
cluster Edit cluster.
instancegroup Edit instancegroup.
Tenemos dos tipos de ediciones disponibles. En este caso vamos a elegir la última opción ya que si ejecutamos la siguiente instrucción que sería la primera opción:
kops edit cluster --name $NAME
No veremos nada relacionado con el número de nodos que tenemos, esto se debe a que no deberíamos crear servidores en AWS directamente. Ya que Kubernetes tiene un enfoque declarativo antes que imperativo cuando a instancias EC2 se refiere.
Así que vamos a utilizar la segunda opción, en lugar de enviar una instrucción imperativa para crear un nuevo nodo, vamos a cambiar el valor del ASG relacionado con los nodos workers. Una vez cambiemos los valores, AWS se asegurará de que se cumpla el nuevo estado deseado. Además de crear el nuevo servidor se encargará de monitorizar que el ASG cumple con el número de nodos deseados y de mantenerlos si hubiera cualquier fallo.
kops edit ig --name $NAME nodes
Y cambiar con el editor vi, los valores maxSize y minSize por el valor 2:
...
image: kope.io/k8s-1.8-debian-jessie-amd64-hvm-ebs-2018-02-08
machineType: t2.small
maxSize: 2
minSize: 2
nodeLabels:
kops.k8s.io/instancegroup: nodes
role: Node
subnets:
- eu-west-1a
- eu-west-1b
- eu-west-1c
...
Aparte hay otra información útil en dicho fichero de configuración temporal, y es que podemos ver que nuestros nodos del clúster por lo menos los workers utilizan como sistema operativo base Debian y que se encuentran replicados por las 3 zonas de disponibilidad que existen en la región.
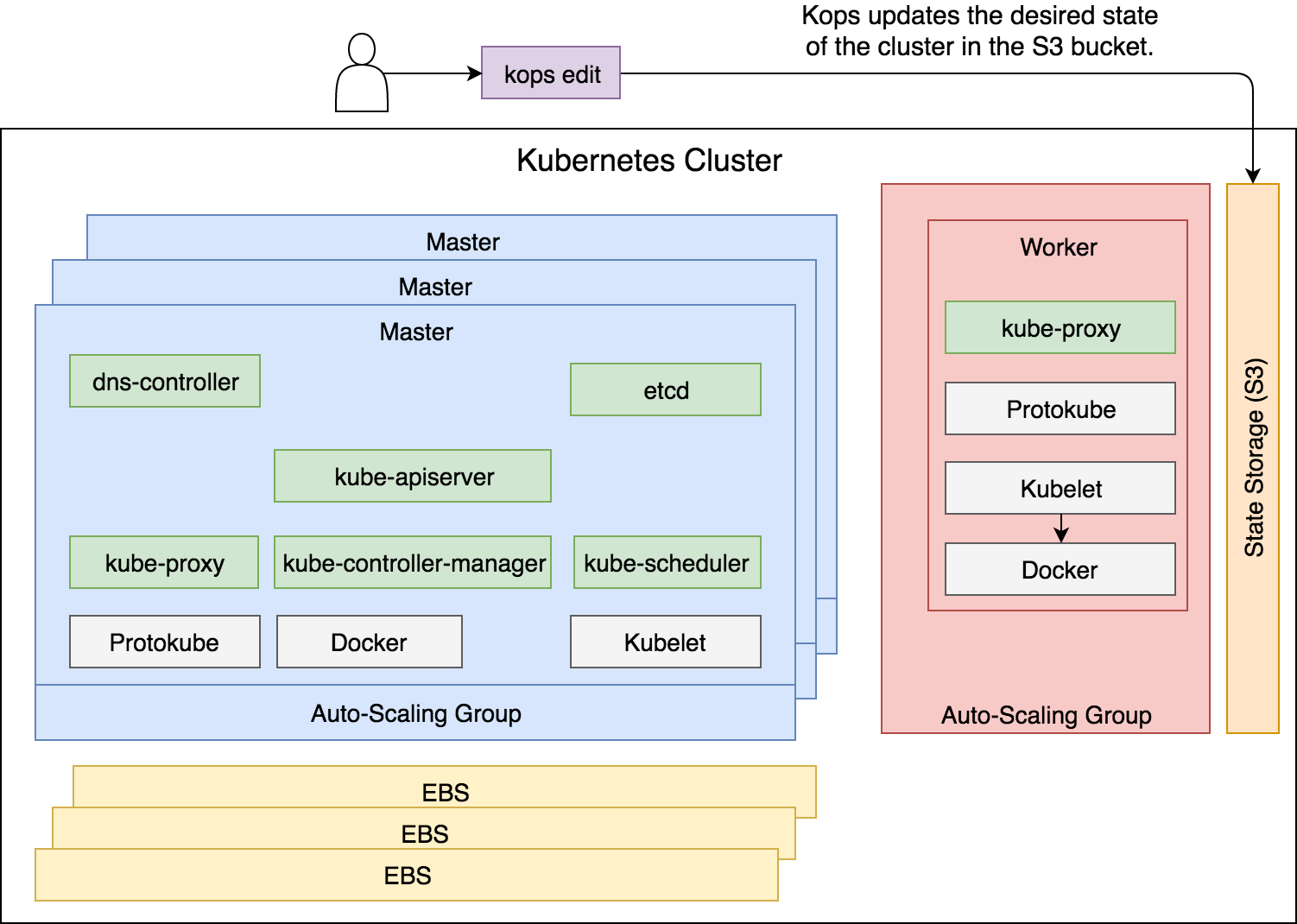
Figura 16 - El proceso que ocurre cuando hacemos un kops edit
Una vez hemos cambiado la configuración, vamos a decirle a kops que queremos actualizar el Clúster para obtener el nuevo estado deseado.
# kops update cluster --name $NAME --yes
I0610 21:48:10.702009 32323 update_cluster.go:291] Exporting kubecfg for cluster
kops has set your kubectl context to proyecto.k8s.local
Cluster changes have been applied to the cloud.
Changes may require instances to restart: kops rolling-update cluster
Como podemos ver en la salida, se han aplicado los cambios a la nube. Pero el último aviso que nos muestra la salida es muy interesante. Ya que esa opción nos permitiría aplicar el nuevo estado deseado sin realizar un downtime en nuestro Clúster, esto se aplicaría a un solo servidor para que el resto sigan estando en ejecución y paralelamente Kubernetes reubicaría los Pods que se estuvieran ejecutando en los nodos que se hayan apagado.
De lo contrario un kops update fuerza directamente al estado deseado a todos los nodos y esto podría provocar un tiempo de inactividad en nuestro clúster.
A continuación vamos a ver los pasos que ha realizado kops, al ejecutar el comando kops update:
- Kops obtiene el nuevo estado deseado almacenado en el S3 Bucket
- Kops envía una petición a la API de AWS para que cambie el valor en la configuración del ASG de los workers.
- AWS modifica dichos valores, incrementandolos a uno.
- El ASG crea una nueva instancia EC2 para cumplir con el nuevo tamaño especificado.
- El componente Protokube instala tanto el servicio Kubelet como Docker en el nodo y crea el archivo de manifiesto con el listado de los Pods.
- Kubelet lee el archivo de manifiesto y ejecuta el contenedor donde se levanta el Pod de kube-proxy.
- Kubelet envía una petición al kube-apiserver (a través del dns-controller) y registra el nuevo nodo y acaba uniéndolo al Clúster. Por último la información sobre el nuevo nodo se almacena en etcd.
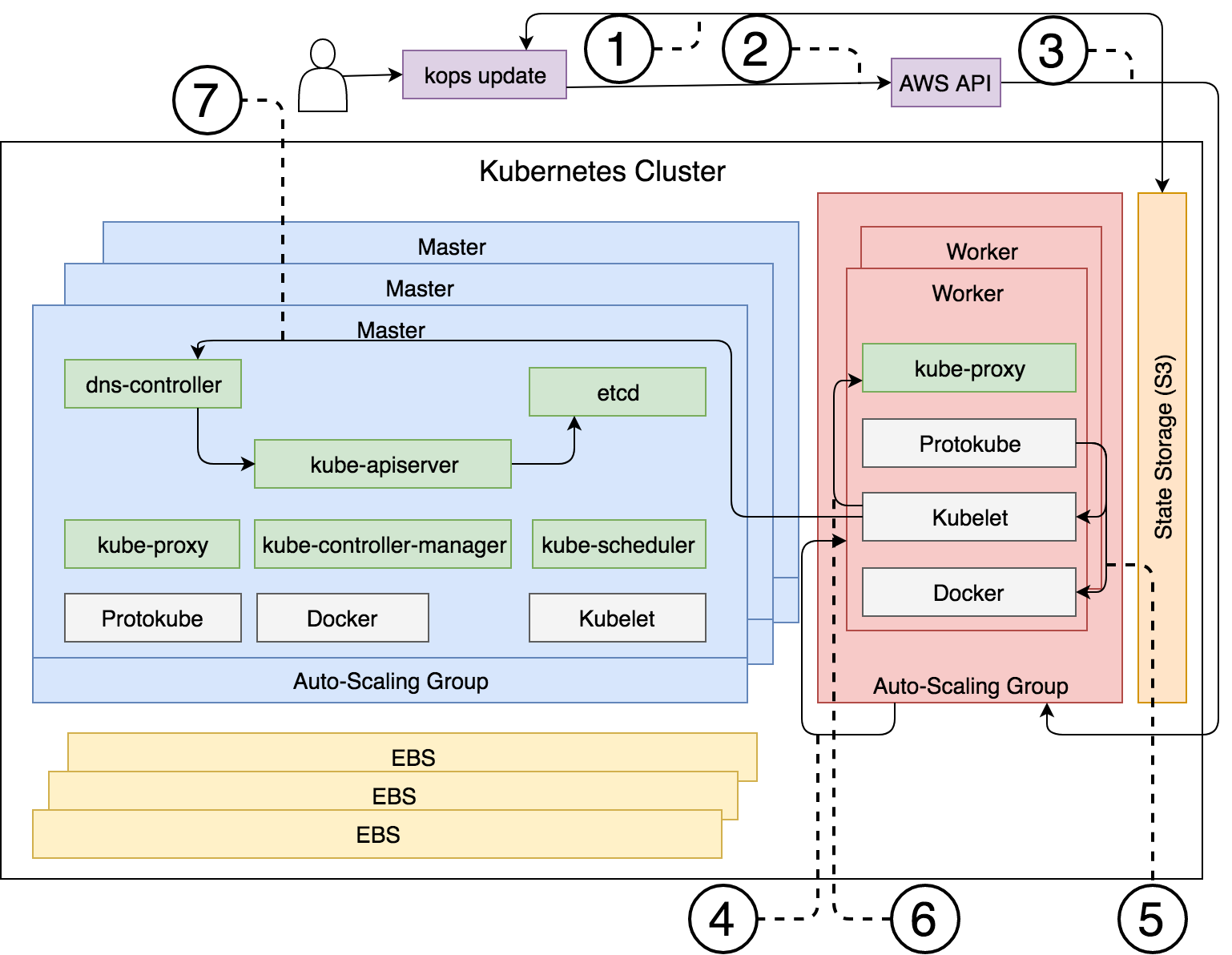
Figura 17 - Proceso a la ejecución del comando kops update
Para verificar que esto se ha realizado, lanzar un kops validate cluster y visualizar el nuevo valor de min y max para el ASG de los workers:
INSTANCE GROUPS
NAME ROLE MACHINETYPE MIN MAX SUBNETS
nodes Node t2.small 2 2 eu-west-1a,eu-west-1b,eu-west-1c
También podemos visualizar que efectivamente agregó el nuevo nodo al cluster:
➜ cluster kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-172-20-107-95.eu-west-1.compute.internal Ready master 2h v1.8.4
ip-172-20-41-196.eu-west-1.compute.internal Ready node 2h v1.8.4
ip-172-20-51-240.eu-west-1.compute.internal Ready master 2h v1.8.4
ip-172-20-86-119.eu-west-1.compute.internal Ready node 20m v1.8.4
ip-172-20-91-5.eu-west-1.compute.internal Ready master 2h v1.8.4
De esta manera podemos agregar o eliminar nodos facilmente y ¿si queremos actualizar las versiones de Kubernetes en los nodos?..
Actualizando la versión de Kubernetes
Manual
El proceso para actualizar el clúster dependerá de lo que queramos hacer, pero si queremos cambiar la versión de Kubernetes, el proceso a ejecutar es similar al realizado para añadir un nuevo nodo worker.
Ahora vamos a editar la definición del cluster:
kops edit cluster $NAME
Procedemos a cambiar el valor v1.8.4 a 1.8.5, guardar y salir.
Una vez modificado el valor, ejecutamos la instrucción para actualizar:
kops update cluster $NAME
En este caso la última linea de la salida nos dirá que debemos ejecutar el comando update con el parametro –yes, aún así también nos ha mostrado en la salida los cambios que se realizarán en el Clúster.
Esto me parece necesario, ya que no es lo mismo agregar un nuevo nodo, que en teoría no afecta al resto del clúster. A actualizar el versionado de Kubernetes en los nodos, que nos puede fastidiar y dejarnos realmente en un estado no deseado.
Si, nos atrevemos a actualizar, ejecutar el comando anterior con la opción de proceder a ello, kops update cluster $NAME --yes.
Ahora nos volverá a pedir que ejecutemos de manera extra, la instrucción kops rolling-update cluster $NAME ya que como hemos comentado en el apartado anterior, no deseamos que nuestro clúster se caiga al cambiar de manera simultanea todos los nodos, si no, que vaya realizandose poco a poco.
➜ cluster kops rolling-update cluster $NAME
NAME STATUS NEEDUPDATE READY MIN MAX NODES
master-eu-west-1a NeedsUpdate 1 0 1 1 1
master-eu-west-1b NeedsUpdate 1 0 1 1 1
master-eu-west-1c NeedsUpdate 1 0 1 1 1
nodes NeedsUpdate 2 0 2 2 2
Must specify --yes to rolling-update.
En la última salida podemos apreciar que necesitamos actualizar cada uno de los ASG, asi que procedemos a ejecutar la instrucción con el --yes. Si razonamos lo hablado, entenderemos que este proceso debe demorarse unos minutos interesantes.. exactamente con las 5 instancias .. alrededor de 31 minutos
Aquí os dejo parte de la salida donde podemos visualizar lo que esta ocurriendo en nuestro Clúster:
I0610 22:26:50.143202 931 instancegroups.go:157] Draining the node: "ip-172-20-91-5.eu-west-1.compute.internal".
node "ip-172-20-91-5.eu-west-1.compute.internal" cordoned
node "ip-172-20-91-5.eu-west-1.compute.internal" cordoned
WARNING: Deleting pods not managed by ReplicationController, ReplicaSet, Job, DaemonSet or StatefulSet: etcd-server-events-ip-172-20-91-5.eu-west-1.compute.internal, etcd-server-ip-172-20-91-5.eu-west-1.compute.internal, kube-apiserver-ip-172-20-91-5.eu-west-1.compute.internal, kube-controller-manager-ip-172-20-91-5.eu-west-1.compute.internal, kube-proxy-ip-172-20-91-5.eu-west-1.compute.internal, kube-scheduler-ip-172-20-91-5.eu-west-1.compute.internal
node "ip-172-20-91-5.eu-west-1.compute.internal" drained
I0610 22:28:21.731177 931 instancegroups.go:273] Stopping instance "i-0d74adcdc394f4849", node "ip-172-20-91-5.eu-west-1.compute.internal", in group "master-eu-west-1b.masters.proyecto.k8s.local".
....
....
node "ip-172-20-41-196.eu-west-1.compute.internal" drained
I0610 22:53:44.572868 931 instancegroups.go:273] Stopping instance "i-08a929acb9332287c", node "ip-172-20-41-196.eu-west-1.compute.internal", in group "nodes.proyecto.k8s.local".
I0610 22:57:46.056320 931 instancegroups.go:188] Validating the cluster.
I0610 22:57:48.909364 931 instancegroups.go:249] Cluster validated.
I0610 22:57:48.909415 931 rollingupdate.go:193] Rolling update completed for cluster "proyecto.k8s.local"!
En la siguiente figura podemos ver más claramente los pasos que se han ido procesando para cada instancia levantada (en este caso sobre una master):
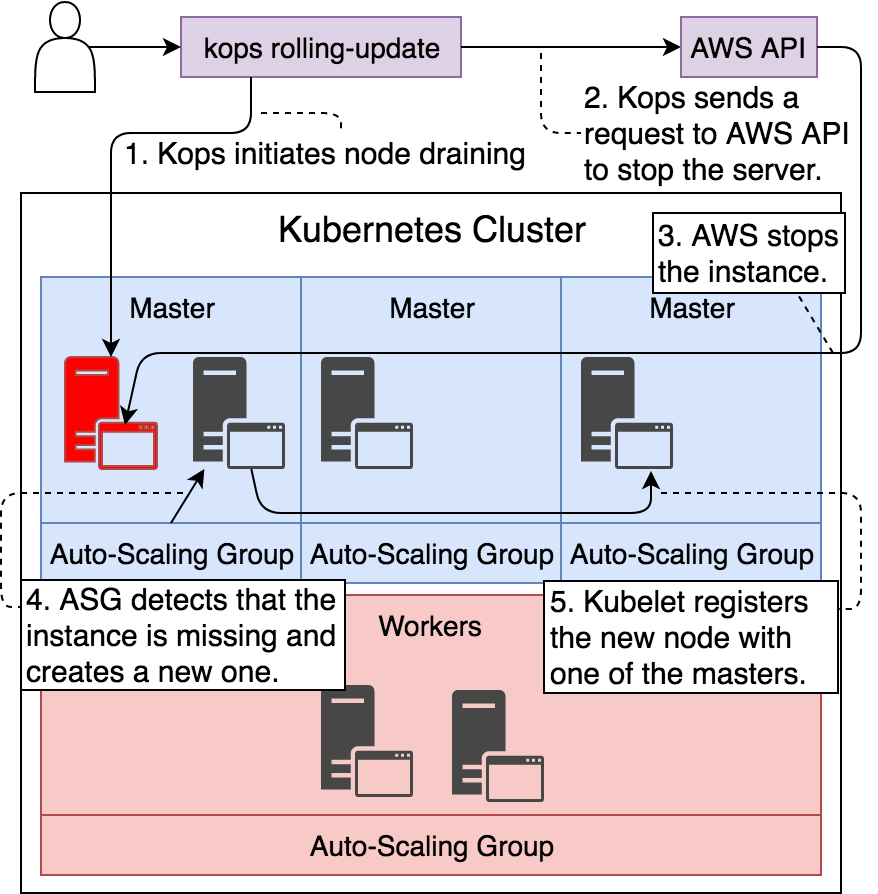
Figura 18 - Rolling upgrade de un nodo master
Tan pronto como se valide que se ha actualizado el primer nodo master, se pasará al siguiente. Esto se demorará entre 10 y 15 minutos el que se vuelva a repetir el mismo proceso con los otros dos masters. Cuando los tres masters se encuentren actualizados. Kops ejecutará el mismo proceso con los dos nodos workers y habrá que esperar aproximadamente otros 10-15 minutos, siendo así el total que se ha demorado el proceso entero de las 5 instancias.
La experiencia al final es positiva, pero se demora demasiado tiempo. También es cierto que esto se debe a que el Auto Scaling Group se toma un 1 minuto o 2 en comprobar que una máquina se encuentra caída y necesita ser reemplazada. Si a esto le añadimos el tiempo para crear e iniciar Docker, Kubelet.. etc y que los contenedores que forman los “pods principales” necesitan ser arrancados, pues ya tenemos el motivo del tiempo necesario…
Volviendo al tema del versionado de nuestros nodos, si comprobamos ahora deberíamos ver que tienen la nueva versión:
➜ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-172-20-102-77.eu-west-1.compute.internal Ready master 1h v1.8.5
ip-172-20-107-252.eu-west-1.compute.internal Ready node 48m v1.8.5
ip-172-20-45-89.eu-west-1.compute.internal Ready master 54m v1.8.5
ip-172-20-68-35.eu-west-1.compute.internal Ready node 42m v1.8.5
ip-172-20-88-88.eu-west-1.compute.internal Ready master 1h v1.8.5
Automáticamente
Lo ideal sería ir actualizando a la última versión estable nuestro clúster. Para estos casos podemos ejecutar el comando kops upgrade cluster.
Pero si es verdad que antes tuvimos que editar nosotros manualmente el estado deseado antes de lanzar el proceso rolling update.
Así que también tenemos la siguiente instrucción para cambiar a la última versión estable y soportada:
➜ cluster kops upgrade cluster $NAME --yes
ITEM PROPERTY OLD NEW
Cluster KubernetesVersion v1.8.5 1.9.6
InstanceGroup/master-eu-west-1a Image kope.io/k8s-1.8-debian-jessie-amd64-hvm-ebs-2018-02-08 kope.io/k8s-1.9-debian-jessie-amd64-hvm-ebs-2018-03-11
InstanceGroup/master-eu-west-1b Image kope.io/k8s-1.8-debian-jessie-amd64-hvm-ebs-2018-02-08 kope.io/k8s-1.9-debian-jessie-amd64-hvm-ebs-2018-03-11
InstanceGroup/master-eu-west-1c Image kope.io/k8s-1.8-debian-jessie-amd64-hvm-ebs-2018-02-08 kope.io/k8s-1.9-debian-jessie-amd64-hvm-ebs-2018-03-11
InstanceGroup/nodes Image kope.io/k8s-1.8-debian-jessie-amd64-hvm-ebs-2018-02-08 kope.io/k8s-1.9-debian-jessie-amd64-hvm-ebs-2018-03-11
Updates applied to configuration.
You can now apply these changes, using `kops update cluster proyecto.k8s.local`
A continuación deberíamos lanzar las instrucciones que ya conocemos, cuando hemos actualizado el versionado de manera manual:
➜ kops update cluster $NAME --yes
➜ kops rolling-update cluster $NAME --yes
El camino para automatizar esto ahora mismo, sería ejecutar algun script o job en un sistema de integracción continua y programarlo cada X tiempo, y aprovechar que con una instrucción automáticamente detecta si existe una nueva versión de Kubernetes estable. Si además agregamos que se levante un entorno de kubernetes de testing, probemos nuestra aplicación o funcionalidad dentro de ella y si funciona, entonces proceder a la actualización del Clúster.. pues mejor mejor ;).
Va siendo hora de empezar a usar nuestro Clúster y conectarnos a él y desplegar alguna aplicación de prueba para verificar que el Clúster funciona.
Accediendo al Clúster
Hasta ahora hemos podido comprobar que podemos interactuar con el Clúster a través de la API utilizando kubectl. Esta comunicación se estable gracias al balanceador de carga (ELB):
➜ cluster aws elb describe-load-balancers
{
"LoadBalancerDescriptions": [
{
...
"ListenerDescriptions": [
{
"Listener": {
"InstancePort": 443,
"LoadBalancerPort": 443,
"Protocol": "TCP",
"InstanceProtocol": "TCP"
},
...
}
],
...
"Instances": [
{
"InstanceId": "i-0162da964c3af9661"
},
{
"InstanceId": "i-07267e9e18710cd62"
},
{
"InstanceId": "i-03e9e25ff27ca3130"
}
],
"DNSName": "api-proyecto-k8s-local-oiqnes-1891537701.eu-west-1.elb.amazonaws.com",
...
"LoadBalancerName": "api-proyecto-k8s-local-oiqnes",
...
}
]
}
Podemos ver en principio como el balanceador que redirecciona el tráfico hacia los masters, solamente esta escuchando en el puerto 443, permitiendo solo las peticiones SSL. Y dicho ELB solamente está administrando solamente a esas 3 instancias, por lo que todavía nos falta la manera de acceder a las aplicaciones que levantemos en nuestros nodos workers.
Desde el lado de vista del usuario, el valor que nos interesa es el del DNSName ya que es el que se usa para poder comunicarnos con la API del servidor de Kubernetes. La función del balanceador aquí es que realmente nuestra petición vaya a un master que se encuentre saludable y no perdamos las peticiones contra un master que este fuera de servicio por cualquier motivo.
Finalmente el nombre del balanceador de carga es api-proyecto-k8s-local-oiqnes en mi caso. Es importante recordar como comienza el nombre, más abajo veremos el motivo.
Podemos verificar que el DNSName es la puerta para acceder a la API, con la siguiente ejecución:
➜ cluster kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: REDACTED
server: https://api-proyecto-k8s-local-oiqnes-1891537701.eu-west-1.elb.amazonaws.com
name: proyecto.k8s.local
...
current-context: proyecto.k8s.local
...
En la siguiente figura vemos donde se sitúa el balanceador de carga en nuestro Clúster:
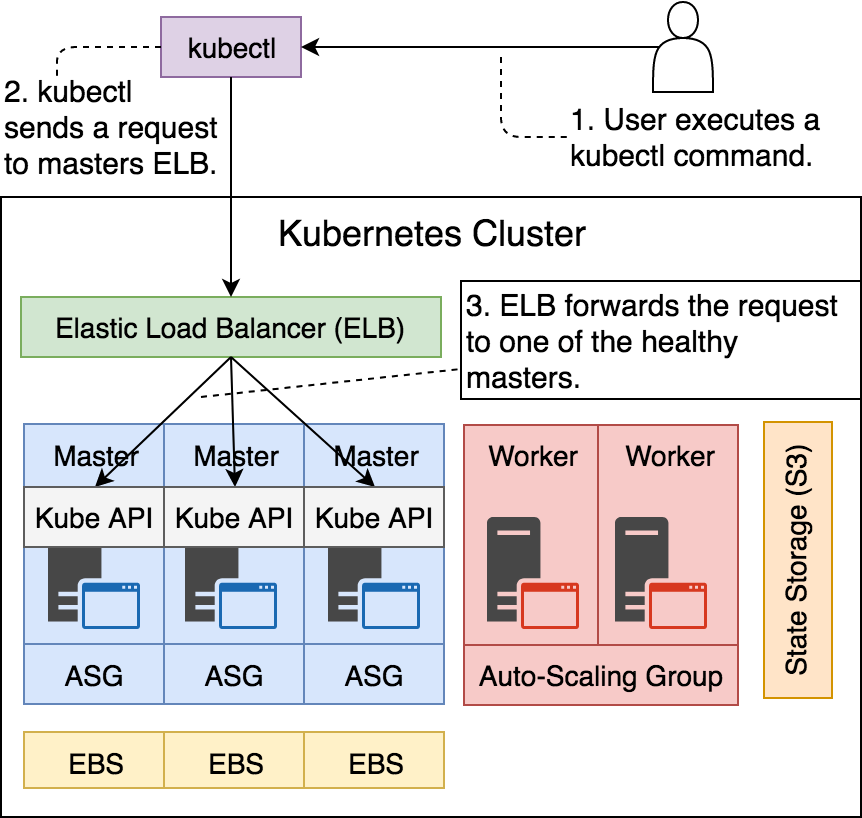
Figura 19 - Balanceador de carga detrás del API Server de Kubernetes
Aunque podamos acceder a este DNS del balanceador de carga, no podemos acceder a nuestras aplicaciones que se encontrarían en los workers incluso si utilizaramos Ingress para canalizar las peticiones a los puertos 80 y 443, no podríamos acceder a ellas. Necesitaríamos otro balanceador de carga para los nodos del ASG de los workers.
Afortunadamente, kops tiene la solución. Podemos utilizar addons para desplegar servicios core de manera adicional.
Aquí podemos comprobar el listado de los addons disponibles: Addons Kops
Para nuestro caso viene genial y esto básicamente es un recurso de Kubernetes definido un fichero en formato YAML. Lo único que tenemos que hacer es indicarle la versión y ejecutar kubectl para crear el recurso:
➜ cluster kubectl create \
-f https://raw.githubusercontent.com/kubernetes/kops/master/addons/ingress-nginx/v1.6.0.yaml
namespace "kube-ingress" created
serviceaccount "nginx-ingress-controller" created
clusterrole.rbac.authorization.k8s.io "nginx-ingress-controller" created
role.rbac.authorization.k8s.io "nginx-ingress-controller" created
clusterrolebinding.rbac.authorization.k8s.io "nginx-ingress-controller" created
rolebinding.rbac.authorization.k8s.io "nginx-ingress-controller" created
service "nginx-default-backend" created
deployment.extensions "nginx-default-backend" created
configmap "ingress-nginx" created
service "ingress-nginx" created
deployment.extensions "ingress-nginx" created
Podemos comprobar que efectivamente se han creado ciertos recursos en el namespace kube-ingress:
➜ cluster kubectl --namespace kube-ingress \
get all
NAME READY STATUS RESTARTS AGE
pod/ingress-nginx-6fbb7d9c7-4q8kz 1/1 Running 0 1m
pod/ingress-nginx-6fbb7d9c7-5gxrr 1/1 Running 0 1m
pod/ingress-nginx-6fbb7d9c7-xgczw 1/1 Running 0 1m
pod/nginx-default-backend-74f9cd546d-xdghs 1/1 Running 0 1m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/ingress-nginx LoadBalancer 100.67.72.122 a55765edc6cfb... 80:32123/TCP,443:30278/TCP 1m
service/nginx-default-backend ClusterIP 100.65.182.220 <none> 80/TCP 1m
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deployment.extensions/ingress-nginx 3 3 3 3 1m
deployment.extensions/nginx-default-backend 1 1 1 1 1m
NAME DESIRED CURRENT READY AGE
replicaset.extensions/ingress-nginx-6fbb7d9c7 3 3 3 1m
replicaset.extensions/nginx-default-backend-74f9cd546d 1 1 1 1m
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deployment.apps/ingress-nginx 3 3 3 3 1m
deployment.apps/nginx-default-backend 1 1 1 1 1m
NAME DESIRED CURRENT READY AGE
replicaset.apps/ingress-nginx-6fbb7d9c7 3 3 3 1m
replicaset.apps/nginx-default-backend-74f9cd546d 1 1 1 1m
Como resultado vemos que se esta ejecutando Ingress dentro de nuestro clúster, donde ha creado:
- Services
- Deployments
- ReplicatSets
- Pods
Aún así todavía no sabemos como acceder al clúster…
Uno de los dos Services que se han creado (ingress-nginx) es un balanceador de carga. Este tipo de servicio expone el servicio de manera externa utilizando su proveedor de cloud, en este caso AWS.
Los servicios NodePort y ClusterIP, a los que se enrutará el balanceador de carga, se crearón automáticamente. Ingress es lo suficientemente inteligente, para interactuar con AWS y crearse y configurarse con el servicio ELB.
Si hemos prestado atención a la salida anterior.. comprobaremos que el servicio de ingress de nginx ha mapeado el puerto 80 con el puerto 32123 TCP y el 443 con el puerto 30278.
Esto significa que desde el interior del clúster podemos envíar solicitudes HTTP a 32123 y HTTPS a 30278.Por otro lado desde que el servicio es un ELB, podemos esperar algunos cambios en la configuración de nuestro AWS ELB.
Vamos a echarle un vistazo al estado de los balanceadores de carga de nuestros clúster:
"ListenerDescriptions": [
{
"Listener": {
"InstancePort": 30278,
"LoadBalancerPort": 443,
"Protocol": "TCP",
"InstanceProtocol": "TCP"
},
"PolicyNames": []
},
{
"Listener": {
"InstancePort": 32123,
"LoadBalancerPort": 80,
"Protocol": "TCP",
"InstanceProtocol": "TCP"
},
"PolicyNames": []
}
],
....
"Instances": [
{
"InstanceId": "i-01ded2bcce0dbf335"
},
{
"InstanceId": "i-09199069f483e29db"
}
],
"DNSName": "a55765edc6cfb11e88f850afca7f6a09-371685899.eu-west-1.elb.amazonaws.com",
Ahora podemos ver como tenemos otro ELB a parte del de la API y que este mapea los puertos 80 y 443 a otros desde el interior del clúster hacia los nodos workers.
Ahora necesariamente vamos a guardar el nombre del nuevo DNSName del ELB tan fácil de recordar en una variable de entorno:
➜ cluster CLUSTER_DNS=a55765edc6cfb11e88f850afca7f6a09-371685899.eu-west-1.elb.amazonaws.com
En el siguiente apartado vamos a desplegar una aplicación de demo y en donde necesitaremos usar este ELB para acceder a ella ;).
Desplegando una app de prueba
A la hora de desplegar nuestra aplicación en nuestro Cluster Kubernetes en AWS es igual que a la hora de desplegarlo por ejemplo en Minikube. Ya que podemos desplegar nuestra definición en un YAML y llevarlo a cualquier proveedor.
Así que no voy a entrar en detalle en como crear desde cero una definición y vamos a utilizar una de demo:
➜ kubectl create -f go-demo-2.yml \
--record --save-config
ingress.extensions "go-demo-2" created
deployment.apps "go-demo-2-db" created
service "go-demo-2-db" created
deployment.apps "go-demo-2-api" created
service "go-demo-2-api" created
Podemos comprobar con la siguiente instrucción si se ha completado el deployment:
➜ kubectl rollout status deployment go-demo-2-api
deployment "go-demo-2-api" successfully rolled out
Una vez muestre la salida anterior, ya podríamos comprobar que funciona nuestra aplicación, en este caso para comprobar este deployment, me valdría con hacer:
➜ curl -i "http://$CLUSTER_DNS/demo/hello"
HTTP/1.1 200 OK
Server: nginx/1.13.9
Date: Sun, 10 Jun 2018 22:45:21 GMT
Content-Type: text/plain; charset=utf-8
Content-Length: 14
Connection: keep-alive
hello, world!
Si recibimos el código de respuesta 200 y el mensaje de hello, world! quiere decir que nuestro Clúster de Kubernetes en AWS funciona.
Cuando se envía una solicitud al ELB dedicado a los nodos workers, este utiliza el algoritmo round-robin para redireccionar la petición http a uno de los nodos saludables. Una vez ha llegado la petición dentro del nodo, es seleccionada por el servicio de nginx, reenviandose a Ingress y desde ahí se deriva a uno de los contenedores que forman la replica del ReplicaSet.
Podemos ver esto mismo en la figura siguiente:
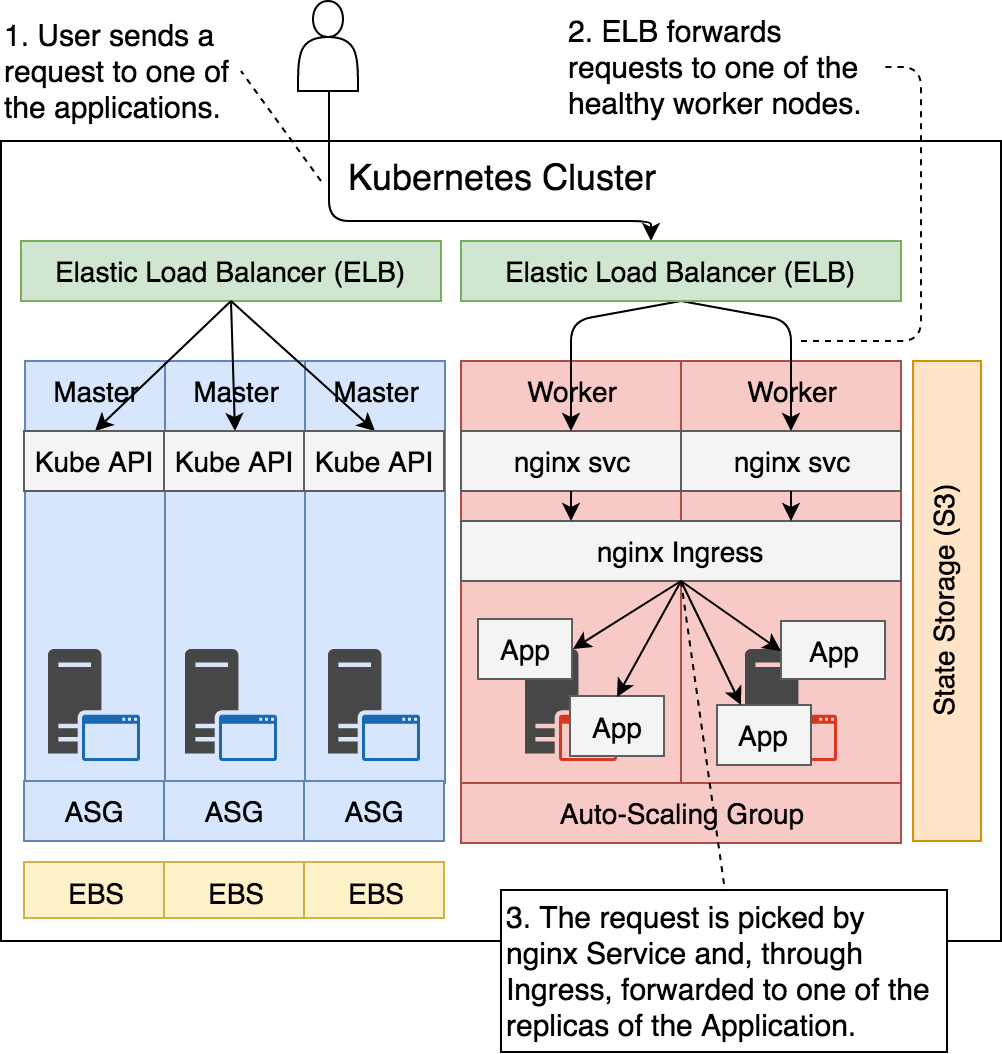
Figura 20 - Balanceador de carga dedicado a los nodos workers
Señalar que los contenedores que forman la aplicación siempre se ejecutan en los nodos workers. Los nodos masters, por otro lado, están dedicado exclusivamente a ejecutar el sistema de Kubernetes. Esto significa que no se pueden combinar los servidores para desplegar los contenedores de una misma aplicación como por ejemplo se puede realizar con Minikube.
Es mejor y más fiable que los masters solamente se dediquen a su tarea y no también de los despliegues de aplicaciones. Esto Kops lo sabe y no nos permite mezclar ambos tipos de nodos a la hora de desplegar una app.
Alta Disponibilidad y Tolerancia a fallos
Un clúster no sería fiable si no fuera tolerante a fallos. Kops se encarga de esto, pero aún así vamos a validar que ocurre.
Vamos a almacenar un listado de las instancias que se encuentran en el ASG de los workers:
➜ aws ec2 \
describe-instances | jq -r \
".Reservations[].Instances[] \
| select(.SecurityGroups[]\
.GroupName==\"nodes.$NAME\")\
.InstanceId"
i-09199069f483e29db
i-01ded2bcce0dbf335
Vamos a almacenar el id de una de las instancias en una variable llamada INSTANCE_ID y vamos a terminarla, ejecutando el comando tail -n 1 vamos a seleccionar solamente una como hemos comentado.
INSTANCE_ID=$(aws ec2 \
describe-instances | jq -r \
".Reservations[].Instances[] \
| select(.SecurityGroups[]\
.GroupName==\"nodes.$NAME\")\
.InstanceId" | tail -n 1)
Y ahora procedemos a terminar con dicha instancia:
➜ aws ec2 terminate-instances \
--instance-ids $INSTANCE_ID
{
"TerminatingInstances": [
{
"InstanceId": "i-01ded2bcce0dbf335",
"CurrentState": {
"Code": 32,
"Name": "shutting-down"
},
"PreviousState": {
"Code": 16,
"Name": "running"
}
}
]
}
Ahora podemos listar las instancias que esten corriendo en el security group de nuestro ASG workers:
aws ec2 describe-instances | jq -r \
".Reservations[].Instances[] \
| select(\
.SecurityGroups[].GroupName \
==\"nodes.$NAME\").InstanceId"
i-09199069f483e29db
Y verificar que efectivamente solamente esta corriendo una instancia.
Esto en teoría el Auto Scaling Group, detectará que el estado deseado no es de la cantidad correcta. Y ejecutará aproximadamente dentro de 1 minuto una nueva instancia en dicho ASG.
Si ejecutamos el siguiente comando veremos como se acaba de levantar la nueva instancia:
➜ cluster kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-172-20-102-77.eu-west-1.compute.internal Ready master 2h v1.8.5
ip-172-20-107-252.eu-west-1.compute.internal Ready node 2h v1.8.5
ip-172-20-45-89.eu-west-1.compute.internal Ready master 2h v1.8.5
ip-172-20-75-70.eu-west-1.compute.internal NotReady node 9s v1.8.5
ip-172-20-88-88.eu-west-1.compute.internal Ready master 2h v1.8.5
Borrar el Clúster
Si por el motivo que sea el Clúster ya no nos sirve o no se esta utilizando lo ideal es borrarlo, ya que por desgracia no es gratuito tener corriendo Kubernetes en un proveedor de nube pública como AWS.
Así que vamos primeramente a guardar los valores que tenemos en las variables de entorno, por si queremos volver a recrear el clúster podamos hacerlo mucho más rápido:
echo "export AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID
export AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY
export AWS_DEFAULT_REGION=$AWS_DEFAULT_REGION
export ZONES=$ZONES
export NAME=$NAME
export BUCKET_NAME=$BUCKET_NAME
export KOPS_STATE_STORE=$KOPS_STATE_STORE
export CLUSTER_DNS=$CLUSTER_DNS" \
>kops-envs
O si hemos cambiado el estado deseado de los ASG a 0 todos y no hemos almacenado las variables de entorno en nuestro perfil de usuario. Y vamos a volver a tocar nuestro Clúster de Kubernetes y no queremos que se nos este cobrando sin utilizarlo.
Para borrar el clúster simplemente ejecutaríamos:
➜ kops delete cluster \
--name $NAME \
--yes
Por otro lado necesitaríamos eliminar el S3 Bucket donde hemos almacenado siempre el estado deseado del Clúster:
➜ aws s3api delete-bucket \
--bucket $BUCKET_NAME
No es necesarioEliminar los recursos de IAM que se crearon al principio del todo, ya que estos no tienen un coste por no usarse.O dicho de otra forma, un costo por horas.